



Наш мозг может и обрабатывать, и хранить информацию, а компаниям для работы с данными требуется множество разных инструментов. И одним из самых важных является корпоративное хранилище данных (enterprise data warehouse, EDW).
В этой статье мы расскажем о том, что же такое EDW, каких типов они бывают и какие функции имеют, а также как они используются в обработке данных. Мы объясним, как корпоративные хранилища отличаются от обычных, какие типы хранилищ данных существуют и как они работают. В первую очередь мы хотим дать вам информацию о ценности для бизнеса каждого архитектурного и концептуального подхода к построению хранилища.
Что такое корпоративное хранилище данных?
Enterprise Data Warehouse (EDW) — это разновидность централизованного корпоративного репозитория, хранящего все исторические бизнес-данные корпорации и управляющего ими. Информация обычно поступает от различных систем, например, из ERP, CRM, физических записей и других неструктурированных файлов. Для подготовки данных к дальнейшему анализу их нужно поместить в единое хранилище. Благодаря этому разные подразделения бизнеса могут запрашивать их и анализировать информацию под различными углами. Однако чтобы данные превратились в полезную информацию, они должны пройти долгий путь. Подробнее о том, как данные поступают из источников в инструменты бизнес-аналитики, можно узнать из представленного ниже видео.
Благодаря хранилищу данных компания может обрабатывать гигантские массивы информации без необходимости администрирования множества разных баз данных. Такая практика является перспективным способом хранения данных для бизнес-аналитики (business intelligence, BI) — набора методик/технологий для преобразования «сырых» данных в полезную информацию. Эта система схожа с тем, как хранит информацию человеческий мозг, и важной её частью является EDW.
Компоненты EDW
Существует множество инструментов, используемых для создания корпоративной платформы хранения данных. Давайте вкратце рассмотрим каждый из компонентов и его функции.
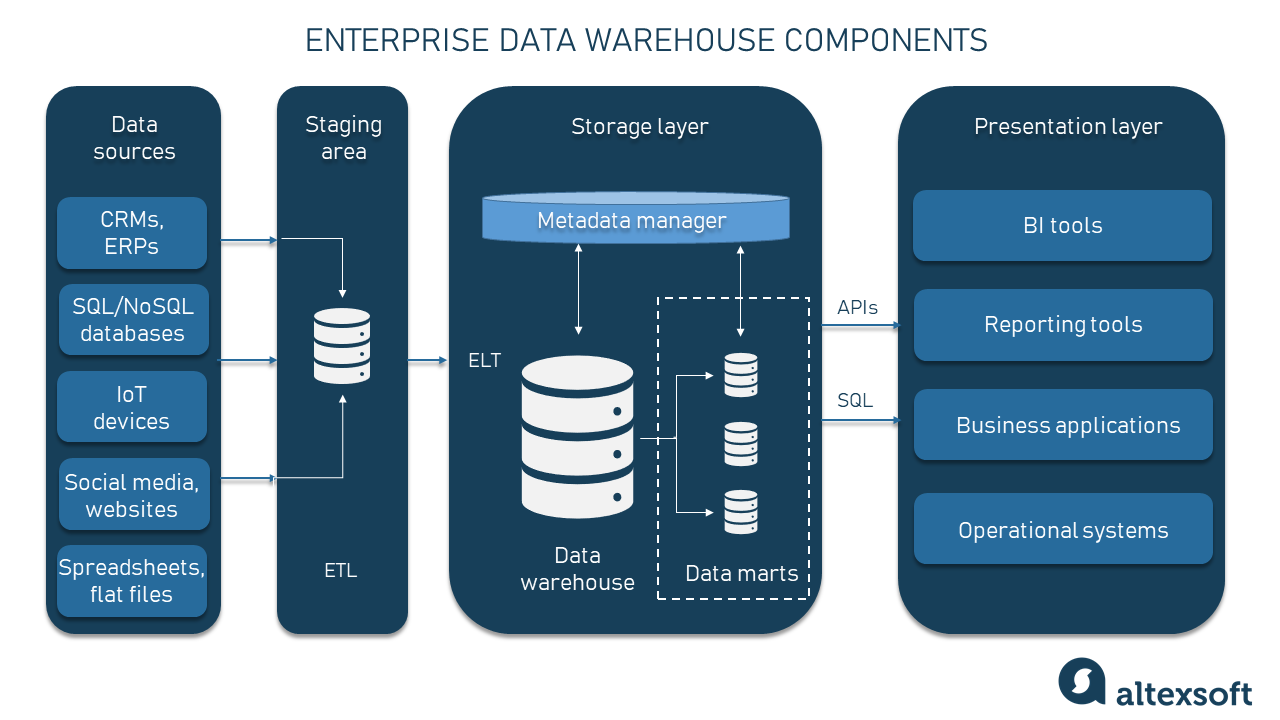
Компоненты EDW
Источники данных. Это все источники данных, откуда берутся «сырые» данные и/или где они хранятся. Они могут быть простыми электронными таблицами, неструктурированными файлами, реляционными базами данных SQL, IoT-системами и так далее.
Слой потребления. Существует два основных подхода к получению данных из источников и передаче их в хранилище. Инструменты ETL (extract, transform, load) и ELT (extract, load, transform) подключаются ко всем источникам данных и выполняют их извлечение, преобразование и загрузку в централизованную систему хранения для удобного доступа и анализа. Различие между методиками ETL и ELT заключается в порядке событий. В ETL преобразование происходит на промежуточном этапе, прежде чем данные попадут в EDW. ELT — это более современный подход, в нём все задачи по преобразованию выполняются внутри хранилища, а промежуточный этап отсутствует.
Промежуточный этап (дополнительный). В случае ETL, промежуточный этап — это место, где данные преобразуются перед EDW. Здесь они очищаются, избавляются от дубликатов, разделяются, объединяются и преобразуются в единый формат, соответствующий модели данных хранилища. Промежуточный этап может также включать инструментарий для управления качеством данных.
Слой хранения. Затем данные загружаются в пространство хранения. В методике ELT здесь они могут подвергаться преобразованиям. Но на этом этапе все основные изменения уже внесены, поэтому данные будут загружаться в свои окончательные модели. Как мы говорили, хранилища данных чаще всего являются реляционными базами данных. Также в хранилище данных имеется система управления базами данных и дополнительное хранилище для метаданных.
Модуль метаданных. Если вкратце, метаданные — это данные о данных. Это объяснения, сообщающие пользователям/администраторам, с какой темой/предметной областью связана эта информация. Эти данные могут быть технической метой (например, указанием исходного источника) или бизнес-метой (например, регионом продаж). Все метаданные хранятся в отдельном модуле EDW и управляются менеджером метаданных. В некоторых случаях, может присутствовать дополнительный слой, созданный поверх всей инфраструктуры; он курирует метаданные наподобие слоя виртуализации данных или слоя data fabric (матрицы данных).
Витрины данных (дополнительные). В некоторых случаях в EDW может существовать множество дополнительных подразделов, называемых витринами данных; они создаются специально под конкретную предметную область, бизнес-функцию или группу пользователей. Например, может существовать отдельная витрина данных для маркетинга и витрина данных для финансового отдела.
Слой представления. Последний строительный блок EDW состоит из инструментов, дающих конечному пользователю доступ к данным. Этот слой, также называемый интерфейсом бизнес-аналитики (BI interface), служит в качестве дэшборда для визуализации данных, бизнес-отчётности и вывода отдельных элементов информации для задач наподобие машинного обучения.
Теперь давайте разберёмся, почему такой репозиторий называется корпоративным хранилищем данных, а не просто хранилищем данных.
Ключевые различия между корпоративным и обычным хранилищем данных
По своей природе, любое хранилище данных — это база данных, всегда соединённая с источниками «сырых» данных при помощи инструментов интеграции данных с одной стороны и аналитических интерфейсов с другой. Они предоставляют пространства для хранения, а также механизмы для преобразования, перемещения и представления данных конечному пользователю. Если это так, почему же мы выделяем корпоративную разновидность хранилища?
Различие между обычным и корпоративным хранилищем данных заключается в гораздо более широком архитектурном разнообразии и функциональности. Из-за сложности своей структуры и размеров EDW разбивают на базы данных меньшего объёма, чтобы конечным пользователям было удобнее выполнять запросы к маленьким базам данных. Учитывая это, мы сосредоточились на сфере корпоративных хранилищ, чтобы раскрыть весь спектр функциональности.
Однако размер хранилища — это не единственное, что определяет его техническую сложность, требования к аналитическим и отчётным возможностям, количество моделей данных и сами данные. Чтобы понять, что делает хранилище тем, чем оно является, давайте глубже рассмотрим его фундаментальные концепции и функциональность.
Концепции и функции корпоративных хранилищ данных
Несмотря на многообразие возможностей, в основе любого хранилища лежат фундаментальные концепции и функции. Эти опорные столбы определяют хранилище как техническое явление.
Служит в качестве всеобъемлющего накопителя данных. Корпоративное хранилище данных — это единый репозиторий для всех корпоративных бизнес-данных, появляющихся в организации.
Отражает исходные данные. EDW получает данные из исходных пространств хранения наподобие Google Analytics, CRM, IoT-устройств и так далее. Если данные разбросаны по множеству систем, управлять ими невозможно. То есть EDW предназначено для того, чтобы обеспечить схожесть изначальных исходных данных в одном репозитории. Так как и внутри, и снаружи компании всегда генерируются новые релевантные данные, прежде чем поток данных попадёт в хранилище, ему требуется специализированная инфраструктура для управления им.
Хранение структурированных данных. Хранящиеся в EDW данные всегда стандартизованы и структурированы. Благодаря этому конечные пользователи могут запрашивать их через интерфейсы бизнес-аналитики и формы отчётов. Именно отличает хранилище данных от озера данных. Озёра данных используются для хранения неструктурированных данных с целью анализа. Однако в отличие от хранилищ, озёра данных больше используются дата-инженерами и дата-саентистами для работы с большими массивами «сырых» данных.
Данные ориентированы на предметную область. Основная цель хранилища — это бизнес-данные, которые могут относиться к различным предметным областям. Чтобы понять, к чему относятся данные, они структурируются на основе конкретной предметной области, называемой моделью данных. Примером предметной области может быть регион продаж или суммарные продажи определённого товара. Кроме того, к данным добавляются метаданные, подробно объясняющие, откуда взялся каждый элемент информации.
Зависимость от времени. Собираемые данные обычно являются историческими, потому что объясняют события прошлого. Чтобы понять, когда и в течение какого времени имела место определённая тенденция, подавляющая часть хранимой информации обычно разделена по временным периодам.
Отсутствие изменений. После помещения в хранилище данные больше никогда из него не удаляются. С данными могут выполняться манипуляции, их могут изменять или обновлять из-за изменений в источнике, однако они никогда не должны удаляться, по крайней мере, конечными пользователями. Поскольку мы говорим об исторических данных, их удаление препятствует задачам аналитики. Тем не менее, раз в несколько лет могут происходить ревизии, позволяющие избавляться от нерелевантных данных.
Разобравшись с базовыми принципами, давайте рассмотрим типы реализаций EDW.
Типы корпоративных хранилищ данных
При создании EDW всегда возможна свобода маневра в техническом проектировании его функций. Хранение и обработка данных специфичны и уникальны для различных типов бизнеса. Всегда существуют варианты структуры системы в зависимости от объёмов данных, аналитической сложности, вопросов безопасности и бюджета.
Хранилище данных внутри компании
Хранилище данных на внутренних мощностях компании считается классическим вариантом EDW — локальное выделенное оборудование и ПО компании в нём используются для единого хранения данных. Когда данные хранятся на физических серверах, не нужно настраивать инструменты интеграции данных между несколькими базами данных. Вместо этого EDW можно соединить с источниками данных через API, чтобы постоянно получать информацию и преобразовывать её в процессе. То есть вся работа выполняется или на промежуточном этапе (пространстве, где данные преобразуются, прежде чем попасть в хранилище), или в самом хранилище.
Классическое хранилище данных считается более совершенным, чем виртуальное (о нём мы поговорим ниже), потому что в нём отсутствует дополнительный слой абстракций. Это упрощает работу дата-инженеров и потоки данных на этапе предварительной обработки, а также отчётность.
Недостатки классического хранилища зависят от конкретной реализации, но для большинства бизнесов они таковы:
- дорогостоящая технологическая инфраструктура (и аппаратная, и программная)
- необходимость найма команды дата-инженеров и специалистов DevOps для создания и поддержки всей платформы данных.
Когда использовать: такой тип EDW подходит для организаций всех размеров, которые хотят обрабатывать свои данные безопасным образом и получать от них максимум. Классические хранилища можно преобразовывать в другие стили архитектур платформ данных, изменять их масштаб с сохранением конфиденциальности данных.
Виртуальное хранилище данных
Виртуальное хранилище данных — это тип EDW, используемый в качестве альтернативы классического хранилища. По сути, это несколько виртуально соединённых баз данных, к которым можно выполнять запросы как к единой системе.
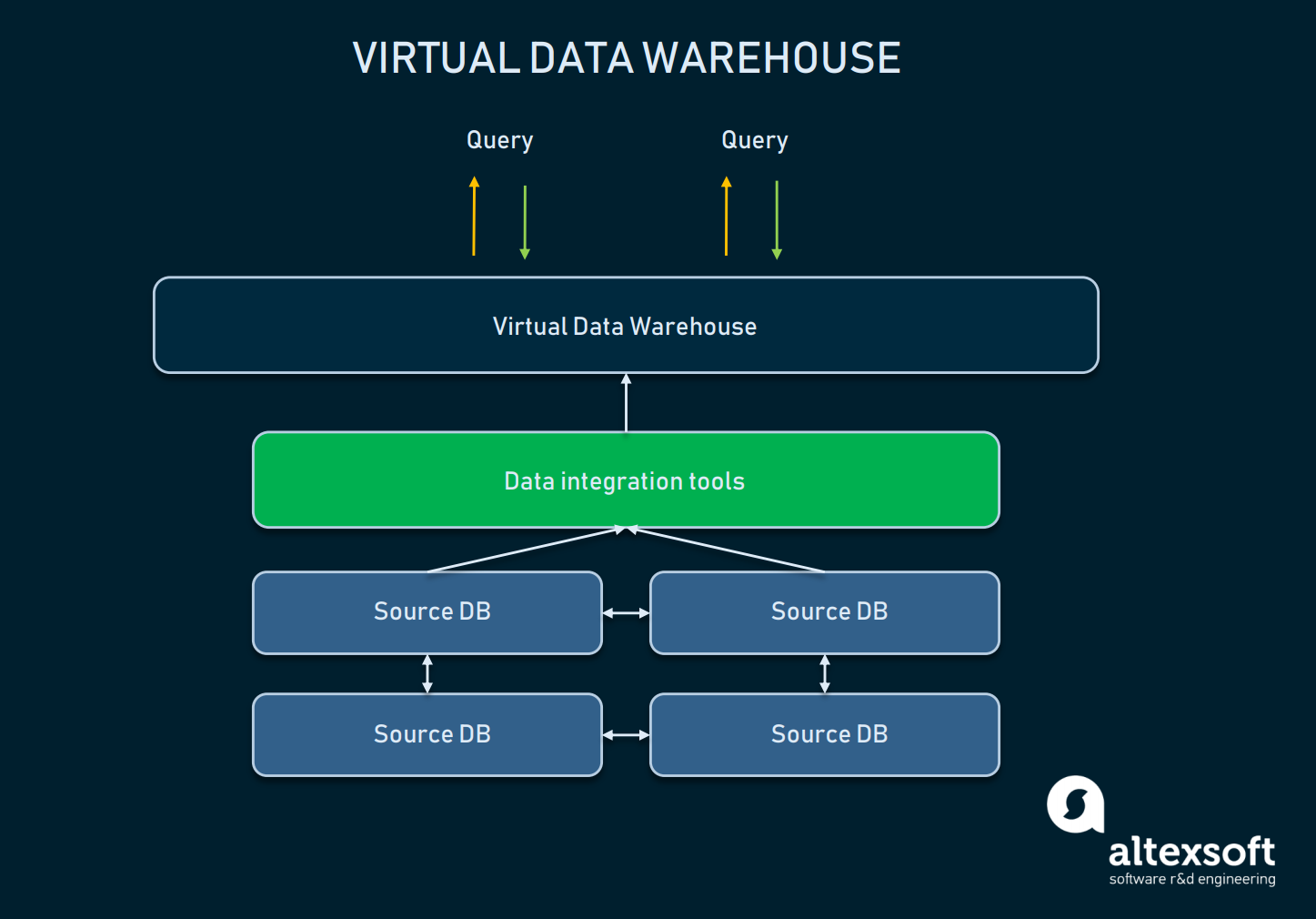
Данные могут оставаться в своих источниках: физически они никуда не перемещаются, но всё равно могут получаться при помощи инструментов аналитики. Виртуальные хранилища можно использовать, если вы не хотите разбираться со всей внутренней инфраструктурой, или если данными легко управлять в исходном виде. Однако такой подход имеет множество недостатков:
- Необходимы постоянное обслуживание ПО и оборудования разных баз данных, а также затраты на них.
- Данным, хранящимся в виртуальном хранилище, всё равно нужно ПО преобразования, чтобы сделать их удобоваримыми для конечных пользователей и инструментов отчётности.
- Сложные запросы данных могут занимать слишком много времени, поскольку все необходимые элементы данных могут располагаться в двух отдельных базах данных.
Когда использовать: виртуальные EDW подходят для бизнесов, имеющих «сырые» данные в стандартизованном виде, которые не требуют сложной аналитики. Также они подходят организациям, не использующим бизнес-аналитику систематически, или желающим начать её применять.
Облачное хранилище данных
Облачное хранилище данных — это центральный репозиторий для информации, который хостится в облаке. В этом случае, база данных предоставляется как управляемый сервис (managed service) поставщика облачных услуг, оптимизированный для аналитики, масштабирования и удобства использования.
Облачные хранилища обычно состоят из слоёв вычислений, хранения и клиента (сервиса). В слое вычислений есть множество вычислительных кластеров узлами, параллельно обрабатывающими запросы. В слое хранения, как понятно из названия, хранятся все виды информации. Слой клиента отвечает за действия по управлению данными.
В данном случае, архитектура облачного хранилища имеет те же преимущества, что и любой другой облачный сервис. Поддержкой его инфраструктуры обычно занимается поставщик облачных услуг, то есть вам не нужно создавать собственные серверы, базы данных и инструментарий для управления хранилищем. Стоимость такого сервиса зависит от объёма памяти и вычислительных мощностей, необходимых для выполнения запросов.
Единственный аспект, который может беспокоить вас — это безопасность данных. Бизнес-данные — это уязвимая информация. Поэтому вам нужно проверить, стоит ли выбранный поставщик услуг доверия в вопросе защиты от утечек и взломов. Это не значит, что хранилище внутри компании более защищено, но в нём безопасность данных находится в ваших собственных руках.
Когда использовать: платформы облачных хранилищ данных — отличный выбор для организаций любого размера, если вам нужно, чтобы всё сделали за вас, в том числе реализовали управляемую интеграцию данных, обслуживание хранилища и поддержку бизнес-аналитики.
Архитектура корпоративного хранилища данных
Хотя существует множество архитектурных решений, тем или иным образом расширяющих возможности хранилищ, мы рассмотрим только самые основные. Если не вдаваться в подробности, весь конвейер данных можно разделить на три слоя:
- Слой «сырых» данных (источников данных)
- Хранилище и её экосистему
- Интерфейс пользователя (инструменты аналитики)
Инструментарий, отвечающий за извлечение, преобразование и загрузку данных в хранилище — это отдельная категория инструментов, называемая ETL. Кроме того, в рамках ETL инструменты интеграции данных выполняются манипуляции с данными до помещения их в хранилище. Эти инструменты работают на участке между слоем «сырых» данных и хранилищем.
Когда данные загружаются в хранилище, они также могут подвергаться преобразованиям. То есть хранилищу потребуется определённая функциональность для очистки/стандартизации/изменения формата данных. Этот и другие факторы определяют сложность архитектуры. Мы будем рассматривать архитектуру EDW с точки зрения потребностей растущей организации.
Одноуровневая архитектура
После завершения конфигурирования интеграции данных мы можем выбрать хранилище данных. В большинстве случаев, хранилище данных — это реляционная база данных с модулями, позволяющими разделять многомерные данные на связанные с конкретной областью для простоты доступа. В самом примитивном виде система хранения может иметь одноуровневую архитектуру.
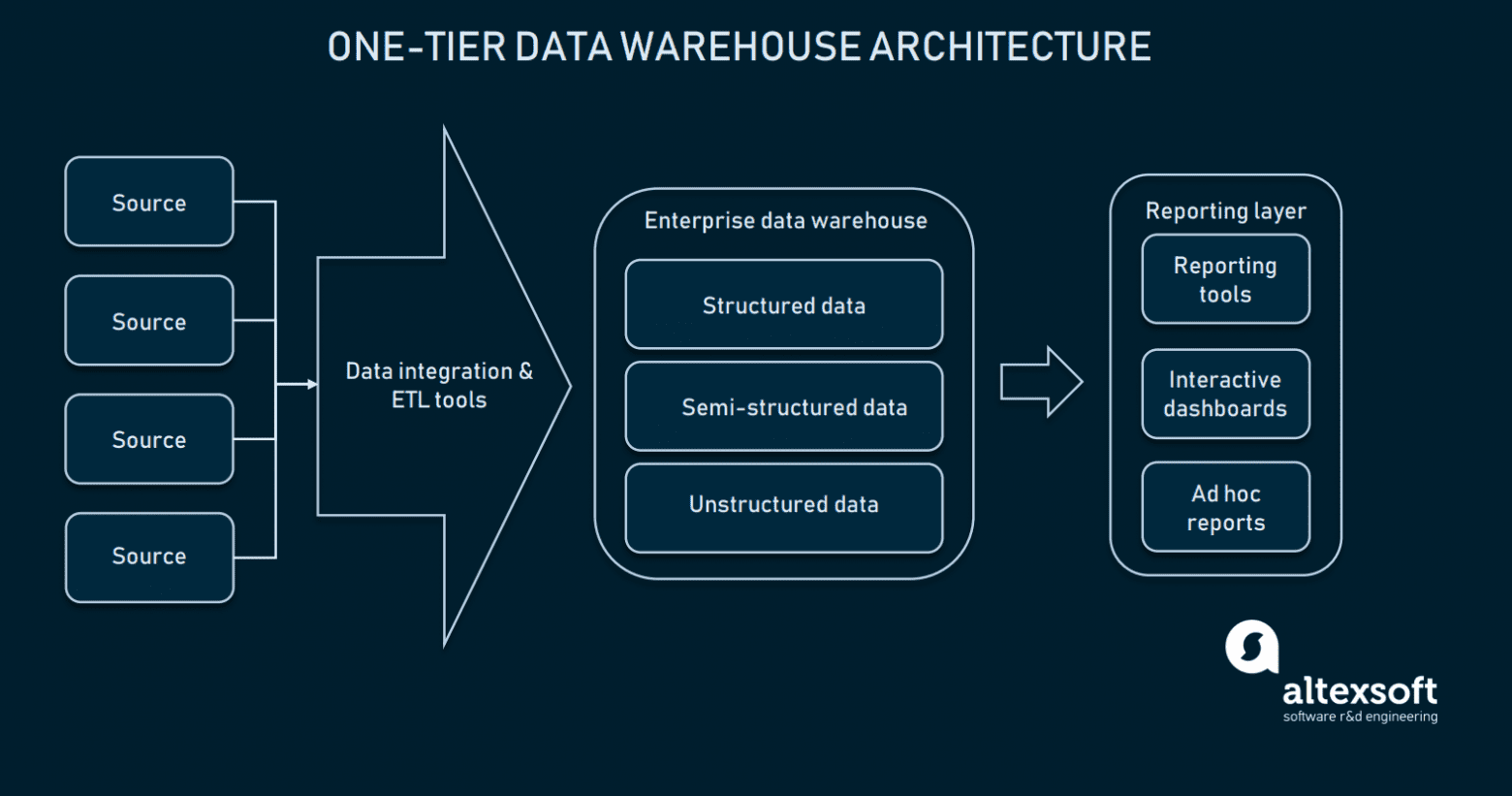
В одноуровневой архитектуре EDW база данных непосредственно соединена с интерфейсами аналитики, к которым могут выполнять запросы конечные пользователи. Из-за установки прямого соединения между EDW и аналитическими инструментами возникает множество сложностей:
- Традиционно считается, что накопитель становится хранилищем, начиная со 100 ГБ данных. Если работать с ними напрямую, это может привести к неаккуратным результатам запросов, а также низкой скорости обработки.
- Для запросов данных непосредственно из хранилища могут потребоваться чёткие формулировки, чтобы система могла отфильтровывать их от нерелевантных данных. Это усложняет работу с инструментами представления.
- Имеются ограниченные возможности обеспечения гибкости и аналитики.
Кроме того, одноуровневая архитектура ограничивает максимальный уровень сложности отчётности. Такой подход редко используется в крупномасштабных платформах данных из-за своей медленности и непредсказуемости. Для выполнения сложных запросов данных хранилище можно расширить при помощи низкоуровневых инстансов, упрощающих доступ к данным.
Двухуровневая архитектура (архитектура витрин данных)
В двухуровневой архитектуре между интерфейсом пользователя и EDW добавляется уровень витрин данных. Витрина данных — это низкоуровневый репозиторий, содержащий информацию, относящуюся к конкретной предметной области. Проще говоря, это ещё одна база данных меньшего размера, дополняющая EDW специализированной информацией для отделов продаж, маркетинга, оперативных отделов и так далее.
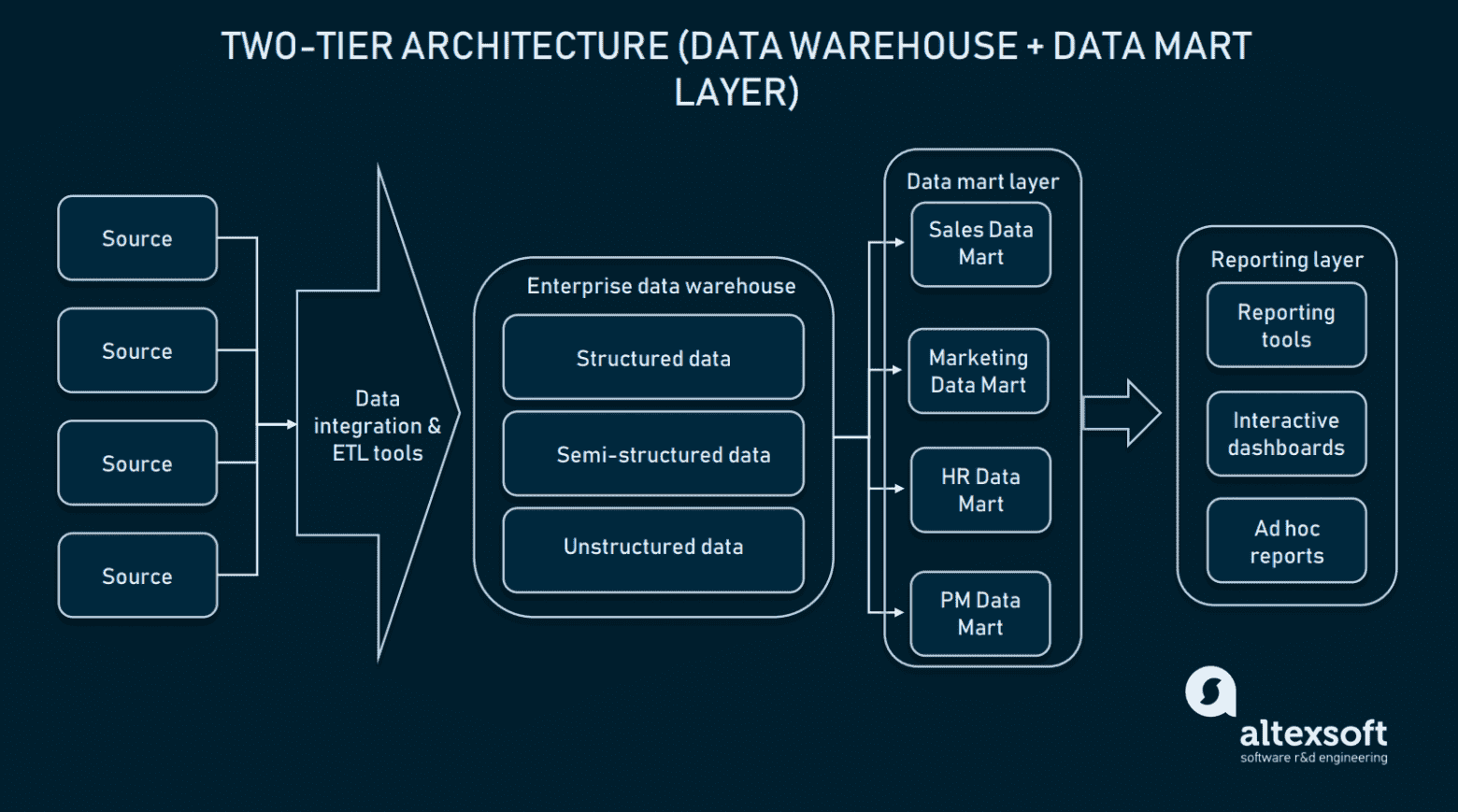
Для создания слоя витрин данных требуются дополнительные ресурсы, необходимые для установки оборудования и интеграции этих баз данных в остальную часть платформы данных. Однако такой подход решает проблему запросов: каждый отдел получает более удобный доступ к данным, поскольку его витрина будет содержать только информацию, относящуюся к конкретной области. Кроме того, витрины данных ограничивают доступ к данным для конечных пользователей, что повышает защищённость EDW.
Трёхуровневая архитектура (аналитическая онлайн-обработка)
Поверх слоя витрин данных компании также используют кубы аналитической онлайн-обработки (OLAP). OLAP-куб — это специфический тип базы данных, представляющей данные из нескольких размерностей. Реляционные данные представляют данные всего в двух измерениях (как в таблицах Excel или Google Sheets), а OLAP позволяет компилировать данные в нескольких измерениях и перемещаться между размерностями.
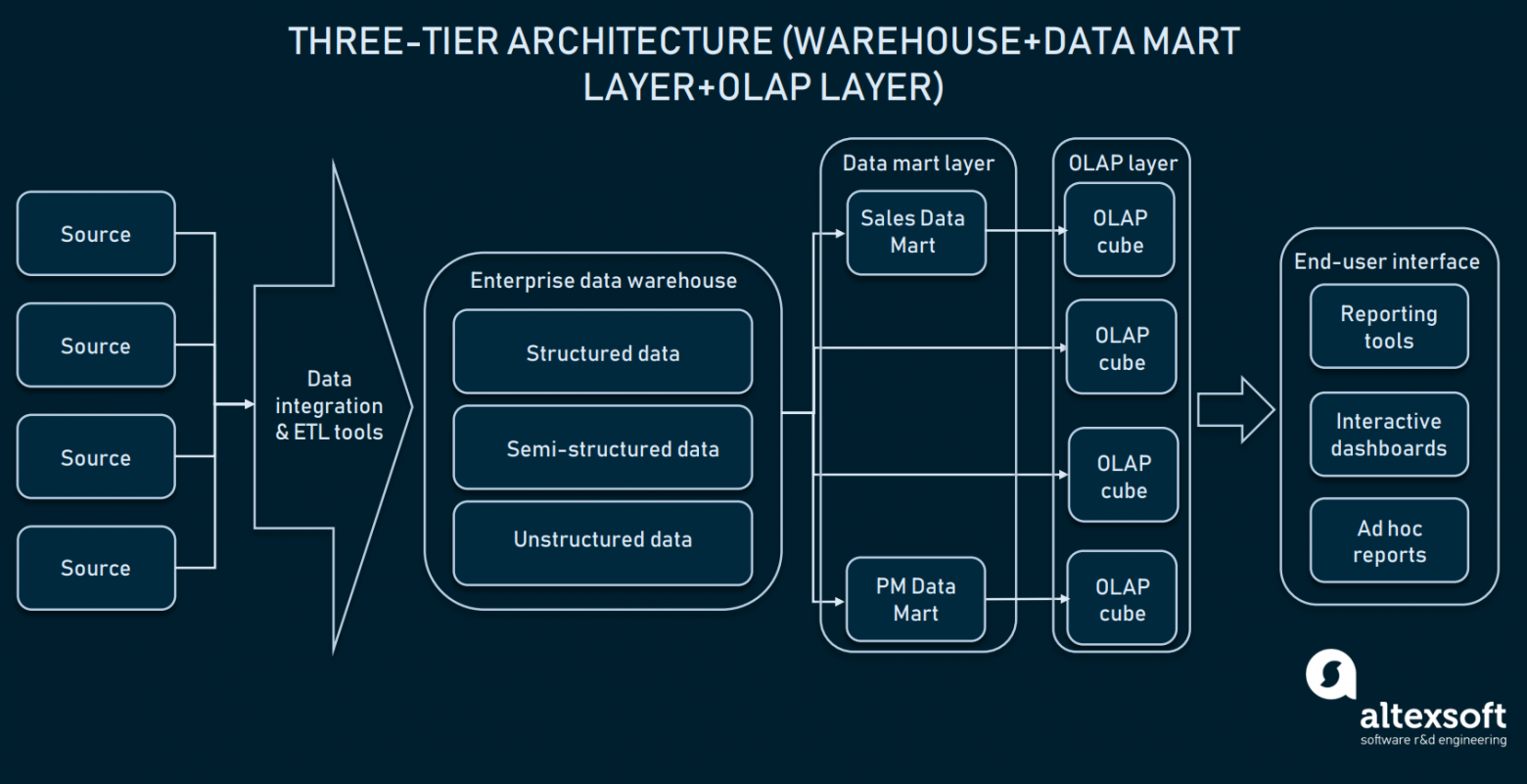
Это довольно сложно объяснить на словах, поэтому давайте рассмотрим удобный пример того, как может выглядеть куб.
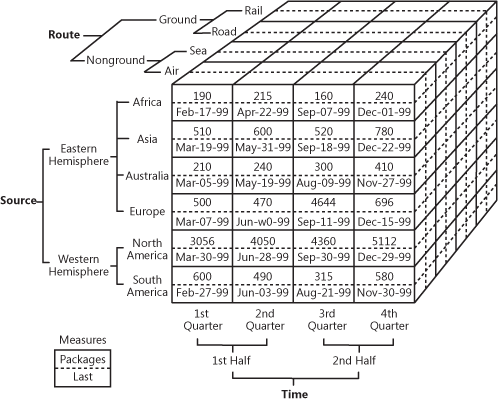
Как видите, куб добавляет данным размерностей. Можно сравнить его с несколькими объединёнными таблицами Excel. Передняя грань куба — это обычная двухмерная таблица, где по вертикали отмечены регионы (Африка, Азия и так далее), а по горизонтали — продажи. Магия начинается, когда мы смотрим на верхнюю грань куба, где продажи сегментированы по маршрутам, а нижняя — по временным периодам. Это и называется многомерными данными.
Ценность OLAP для бизнеса в том, что он позволяет пользователям разрезать и перемешивать данные для компилирования подробных отчётов. Если кубы оптимизированы для работы с хранилищами, их можно использовать и напрямую с EDW для предоставления доступа ко всем корпоративным данным, и по отдельности с каждой витриной данных. Почти все реализации поставщики хранилищ предоставляют в своих реализациях OLAP как сервис. Например, изучите документацию Microsoft по инструменту OLAP компании.
Выше мы обсудили высокоуровневую структуру EDW, применяемую для решения организационных потребностей. Теперь мы рассмотрим технические компоненты, из которых может состоять хранилище.
Разница между хранилищем данных, озером данных и витриной данных
Говоря об архитектуре систем хранения данных, нужно упомянуть такие альтернативы, как использование вместо хранилища витрины или озера данных. Часто их объединяют в одно понятие, поэтому мы уточним определения.
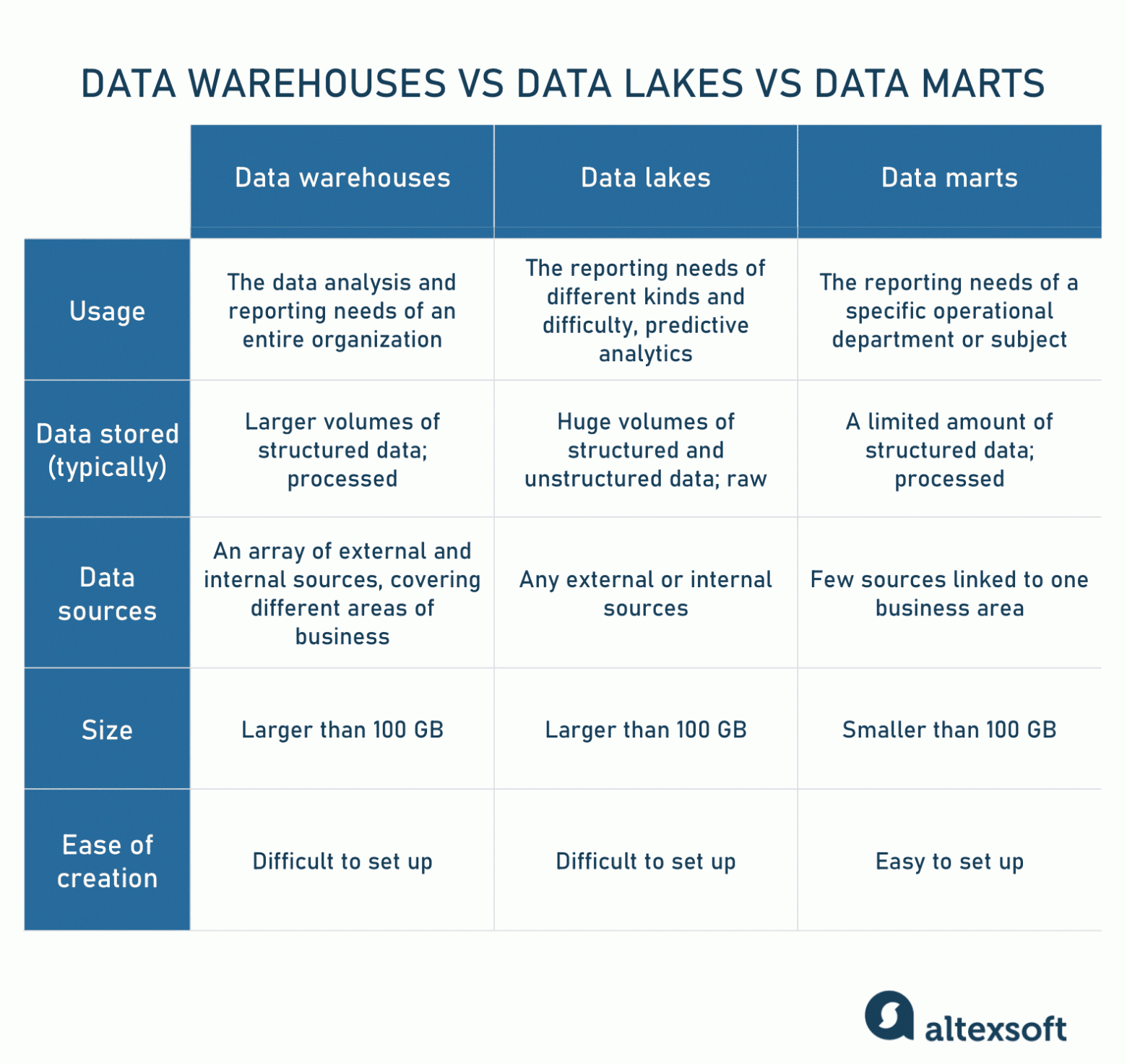
Хранилища данных в своём традиционном виде предназначены для хранения структурированных данных, представленных в виде удобных столбцов и строк, что упрощает получение исчерпывающих результатов инструментами и конечными пользователями. Хранилища, в основном используемые для бизнес-аналитики, имеют размер от 100 ГБ и до бесконечности. Они получают данные от большого количества внешних и внутренних источников, покрывающих различные области бизнеса. Для полного конфигурирования хранилищ данных внутри компании могут потребоваться месяцы.
Озёра данных используются для хранения огромного количества различной информации, в том числе структурированных, неструктурированных и полуструктурированных данных в «сырых» форматах. Озёра часто используются для машинного обучения, обработки big data и data mining. Последние два года озёра данных используются для бизнес-аналитики: «сырые» данные загружаются в озеро и преобразуются, что является альтернативой процессу ETL. Хотя такой подход имеет плюсы и минусы, озёра данных могут быть слишком запутанными для хранения структурированных данных. Кстати, существует новый гибридный вариант, называющийся data lakehouse.
Также кто-то может путать хранилище данных в целом и витрин данных.
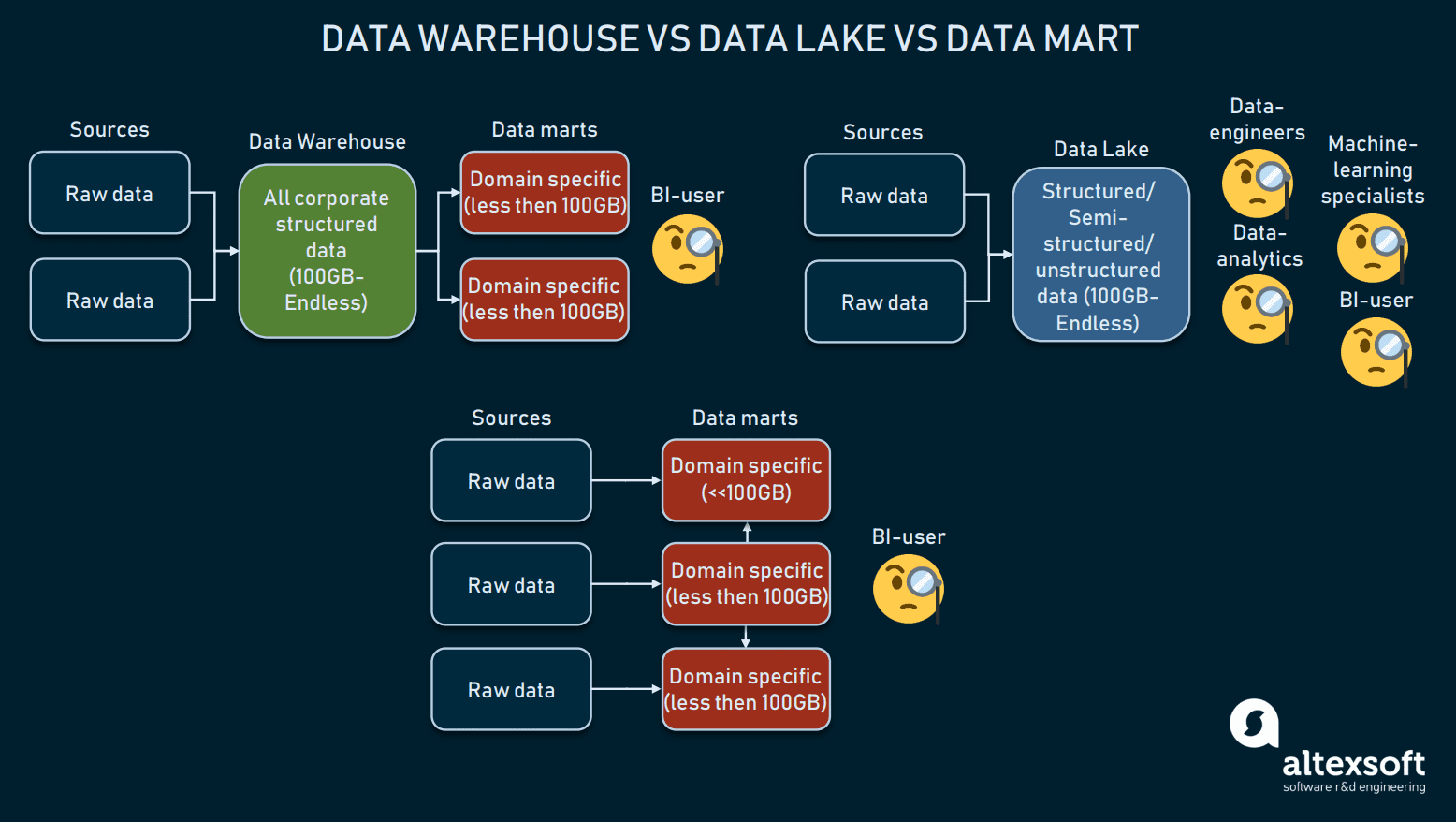
Витрины данных — это реляционные базы данных в определённой предметной области, содержащие только подмножество данных хранилища, относящееся к конкретному отделу компании, например, к финансовому. Также они могут использоваться в качестве альтернативы хранилищам. Однако из-за их маленького размера (обычно менее 100 ГБ), витрины данных вряд ли могут использоваться крупными корпорациями. Чаще всего витрины используются для сегментирования хранилища на более удобные в работе части. Витрины данных получают информацию от относительно небольшого количества источников, обычно содержат структурированные данные и требуют меньше времени на настройку: обычно 3-6 месяцев в случае решений, находящихся внутри компании.
Технологии корпоративного хранения данных
Понимание существующих инструментов корпоративных хранилищ данных поможет вам разобраться в том, что конкретно соответствует вашим требованиям к платформе данных. На планирование создания хранилища может уйти несколько лет, потраченных на планирование и тестирование, поскольку даже самый простейший его вид имеет огромный масштаб.
Владельца бизнеса может запутать количество используемых вариантов и технологий, поэтому жизненно необходимо консультироваться со специалистами в сфере хранения данных, ETL и бизнес-аналитики. Специалисты способны помочь с техническим аспектом, однако чтобы задать цели для бизнеса, нужно говорить с теми, кто использует в своей работе реальные данные.
В последнее время в создании технологий организационного уровня всё более стандартными становятся облачные/безоблачные технологии. На рынке есть бесчисленное количество поставщиков, предоставляющих услуги data warehousing-as-a-service — это значит, что вы сможете использовать вычислительные мощности и пространство, принадлежащие поставщикам облачных услуг. И в большинстве случаев в рамках своего инструментария бизнес-аналитики поставщики предлагают полностью управляемое масштабируемое хранение данных.
Ниже перечислены самые популярные продукты для облачного хранения данных.
Amazon Redshift — это облачное корпоративное хранилище данных, являющееся частью облачной вычислительной платформы Amazon. Оно позволяет выполнять параллельную обработку больших объёмов данных, соответствующих потребностям компании. Поскольку Redshift является публичным поставщиком облачных услуг, он имеет уклон в сторону самостоятельного управления, то есть для управления ресурсами и серверами вам потребуется команда дата-инженеров. Цена сервиса начинается от $0,25 за час и может масштабироваться до петабайтов данных и тысяч параллельно работающих пользователей.
Google BigQuery — это мультиоблачное хранилище данных, предоставляющее возможности одновременного выполнения запросов к большим объёмам данных различными пользователями. Это serverless-технология, то есть всем управлением должны заниматься вы; слои вычислений и хранения разделены. BigQuery — высокопроизводительное и масштабируемое решение. Существуют тарифы с фиксированной ставкой или подписки по требованию.
Snowflake — это облачное serverless-хранилище данных, построенное поверх технологий AWS. Так как оно предоставляется как решение SaaS, вам не придётся настраивать виртуальное или физическое оборудование, поскольку эти задачи взял на себя Snowflake. Сервис набрал популярность благодаря предоставлению гибких, быстрых и простых в использовании решений для хранения данных и аналитики. Пользователю достаточно лишь выбрать количество и размер вычислительных кластеров. О ценах поставщика можно узнать на этой странице.
Более подробную информацию про облачные хранилища данных, их производительность, возможности интеграции и так далее можно найти в отдельной статье, посвящённой сравнению ключевых игроков на рынке облачного корпоративного хранения данных.