



Изъяны в данных могут привести к различным результатам. Например, клиенту Skyscanner Джеймсу Ллойду на пути из Крайстчёрча (Новая Зеландия) в Лондон предложили подождать в Банкоке 413 786 часов, или 47 лет. Эта история стала виральной благодаря чувству юмора SMM Skyscanner по имени Джен, ответившей на вопрос Джеймса о том, что он может делать все эти годы.
{kind=link}
Использование ошибочных данных может приводить к трагическим событиям, особенно в медицинской сфере. Дэвид Лошин в статье The Practitioner’s Guide to Data Quality Improvement упоминает случай 2003 года с Джесикой Сантиллан, погибшей из-за некачественной сердечно-лёгочной трансплантации. Хирург использовал органы донора с несовместимой группой крови. Ошибочная информация о группе крови вызвала хирургические осложнения, приведшие к смерти.
Низкокачественные данные также могут препятствовать и замедлять интеграцию бизнес-аналитики и прогностической аналитики на основе ML. Руководители компаний США, участвовавшие в опросе Data trust pulse, проведённом PricewaterhouseCoopers, указали, что ненадёжные данные — одно из препятствий к монетизации данных. «Во многих из исторических данных компании, собиравшихся хаотически, могут отсутствовать нужные подробности и точность, необходимые для работы с ИИ и другими технологиями автоматизации», — говорится в результатах опроса.
Так как от использования компанией надёжной информации зависит производительность труда, а иногда и жизни людей, она должна разработать и реализовать стратегию контроля качества данных.
Давайте подробно раскроем концепцию качества данных. В этой статье мы поговорим о том, какие специалисты участвуют в процессах обеспечения качества данных и как они могут сделать свой вклад. Также мы изучим техники и инструменты для повышения качества данных и обеспечения уровня, позволяющего компании достигать своих бизнес-целей.
Что такое качество данных? Размерности качества данных
Качество данных отражает степень, в которой данные соответствуют стандартам или ожиданиям пользователей. Высококачественные данные можно легко обрабатывать и интерпретировать для различных целей, например, для планирования, отчётности, принятия решений и выполнения основной деятельности.
Но какие данные можно считать высококачественными? Мнения о том, какие признаки определяют качество данных, могут различаться не только в разных отраслях, но и на уровне компании. Для оценки качества специалисты рекомендуют использовать разные сочетания аспектов и признаков данных. Эти измеримые категории называются размерностями качества данных.
В 1996 году профессоры Ричард Ван и Диана Стронг описали в статье Beyond Accuracy: What Data Quality Means to Data Consumers свою концептуальную структуру качества данных. Авторы исследования рассматривали четыре категории качества данных: внутреннюю, контекстуальную, репрезентативную и по степени доступности. Каждая категория содержала несколько размерностей (суммарно 15).

В Data Quality Assessment Framework (DQAF), разработанном Международным валютным фондом, учитывается пять размерностей качества данных:
- Целостность — статистика собирается, обрабатывается и распространяется на основе принципа объективности.
- Методологическая надёжность — статистика создаётся на основе международных принятых руководств, стандартов и рекомендаций.
- Точность и надёжность — исходные данные, используемые для компилирования статистики, своевременны, взяты из исчерпывающих программ сбора данных, учитывающих специфические для страны условия.
- Удобство обслуживания — статистика согласована с массивом данных, по времени и с крупными массивами данных, а также регулярно подвергается ревизиям. Периодичность и своевременность статистики соответствуют общемировым стандартам распространения.
- Доступность — данные и метаданные представлены понятным образом, статистика актуальна и легкодоступна. Пользователи могут получать своевременную и компетентную помощь.
В DQAF входит семь структур для оценки и поддержания единых стандартов качества (национальные счета, индекс стоимости жизни, валютный, статистика государственных финансов и другие виды статистики).
По мнению специалистов, самыми популярными размерностями качества являются следующие:

Специалистка по качеству данных Лаура Себастиан-Коулман в статье Measuring Data Quality for Ongoing Improvement сообщает, что функция размерностей качества данных схожа с функцией длины, ширины и высоты, описывающей размер физического объекта. «Множество размерностей качества данных может использоваться для определения ожиданий (стандартов, относительно которых выполняются измерения) качества нужного массива данных, а также для измерения состояния имеющегося массива данных», — объясняет Себастиан-Коулман.
Размерности качества данных также позволяют отслеживать, как со временем изменяется качество данных, хранимых в различных системах и/или отделах. Эти атрибуты — один из строительных блоков любого проекта по обеспечению качества данных. Разобравшись с тем, по каким размерностям качества данных вы будете оценивать свои массивы данных, вы сможете задать метрики. Например, количество или процент дубликатов записей будет показателем уникальности данных.
Теперь давайте рассмотрим план действий по реализации программы обеспечения качества данных в организации.
Управление качеством данных: как его реализовать и как оно работает
Управление качеством данных (DQM) — это серия практик, направленных на повышение и поддержание качества данных в структурных единицах компании. Специалист по управлению данными Дэвид Лошин подчёркивает непрерывность природы DQM. Специалист замечает, что этот процесс включает в себя «замкнутый круг» выполнения наблюдений, анализа и совершенствования информации. Цель этого круга — упреждающе контролировать качество данных, а не устранять изъяны только после их выявления и не сталкиваться с последствиями этих изъянов.
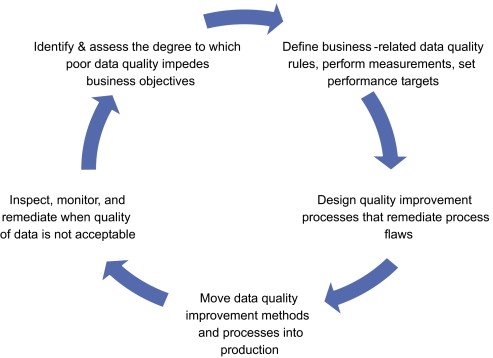
Давайте исследуем каждый из этих пяти этапов, а также процессы, протекающие внутри.
1. Определение влияния плохих данных на показатели при помощи оценки качества данных
В первую очередь аналитик качества данных исследует данные, чтобы найти потенциальные проблемы, вызывающие задержки в конкретных операциях, а значит, снижающие доходы и влияющие на прибыль. Качественное исследование данных даёт базовое понимание того, какие изъяны в данных сильно влияют на бизнес-процессы. Затем специалист излагает требования к качеству данных и указывает критически важные размерности качества данных, которые должны использоваться в компании.
Далее команда приступает к оценке качества данных при помощи методик сверху вниз и снизу вверх. Методика сверху вниз позволяет понять, как сотрудники создают и используют данные, с какими проблемами данных они сталкиваются в процессе, и какие из них наиболее критичны. Также оценка данных позволяет определить операции, на которые сильнее всего влияют данные низкого качества.
Аналитик качества данных может исследовать способ организации данных в базах данных, опрашивать пользователей лично или устраивать опросы, в которых пользователи могли бы документировать проблемы.
Методика снизу вверх использует инструменты и техники статистики и анализа данных, например, профилирование данных. В профилировании данных применяются различные статистические и аналитические алгоритмы и бизнес-правила для исследования содержимого массивов данных и характеристик их элементов данных. Существует три типа профилирования данных:
- Исследование структуры (структурный анализ) используется для того, чтобы проверить, целостны ли данные и правильно ли они форматированы. Один из способов изучения структуры записей данных — сопоставление паттернов. Также для проверки валидности данных аналитики могут проверять статистику в данных, например, минимальные и максимальные значения, медианные и средние значения или стандартные отклонения.
- Исследование содержимого подразумевает изучение отдельных записей данных в базе данных для выявления нулевых или неверных (неверно форматированных) значений.
- Исследование взаимосвязей заключается в понимании взаимосвязей между массивами данных, записями данных, полями или ячейками баз данных. Исследование взаимосвязей начинается с изучения метаданных. Этот анализ позволяет выявлять и устранять такие проблемы, как дубликаты, которые могут возникать в несогласованных массивах данных.
Затем аналитики могут проконсультироваться относительно выявленных проблем данных со специалистами в предметной области.
2. Определение правил и метрик обеспечения качества данных
Сначала аналитики качества данных компилируют результаты оценки данных с упором на элементы данных, которые являются критически важными для нужд конкретного пользователя. «Результаты эмпирического анализа выявляют типы измерений, которые можно использовать для оценки уровня качества данных в контексте конкретного бизнеса», — рассказывает Дэвид Лошин в The Practitioner’s Guide to Data Quality Improvement.
Затем аналитики качества данных выявляют корреляцию влияния на бизнес и изъянов в данных при помощи заданных бизнес-правил. Благодаря этому специалисты задают метрики, которые они будут использовать для обеспечения достаточного уровня точности данных, чтобы их можно было использовать для производственных или аналитических нужд. Они выясняют у пользователей данных пороговые значения приемлемости значений метрик. Данные, имеющие значения метрик ниже приемлемых уровней, не отвечают ожиданиям пользователей и должны быть усовершенствованы, чтобы устранить отрицательное влияние на операции. Интеграция пороговых значений с методиками измерения позволяет создать структуру метрик качества данных.
3. Определение стандартов данных, стандартов управления метаданными, правил валидации данных
После выявления влияния некачественных данных, изучения данных, определения правил и метрик качества данных наступает время для внедрения техник и действий по повышению качества. То есть задача на этом этапе заключается в документировании единых правил использования данных и метаданных на протяжении всего жизненного цикла данных.
Стандарты данных. Стандарты качества данных — это договорённости о вводе, презентации, форматировании и обмене данными, применяемые во всей организации.
Стандарты управления метаданными. Политики и правила создания и обслуживания метаданных — базовое требование для успешных проектов аналитики данных и data governance. Стандарты управления метаданными можно сгруппировать в три категории:
- Бизнес-стандарты — использование бизнес-терминологии и определений в различных контекстах бизнеса, применение акронимов; параметры уровней безопасности данных и конфиденциальности.
- Технические стандарты — структура, формат и правила хранения данных (например, формат и размер для индексов, таблиц и столбцов в базах данных, моделях данных)
- Операционные стандарты — правила использования метаданных, описывающих события и объекты в процессе ETL (например, дата загрузки в ETL, дата обновления, показатель уровня достоверности)
Стоит отметить, что некоторые практикующие специалисты рассматривают операционные метаданные как технические.
Правила валидации данных. Правила валидации данных используются для оценки несоответствий в данных. Разработчики пишут правила валидации данных и интегрируют их в приложения, чтобы инструменты могли идентифицировать ошибки, например, даже в процессе ввода. Правила валидации данных позволяют обеспечивать проактивное управление качеством данных.
Также критически важно определиться с тем, как отслеживать проблемы в данных. В логе отслеживания проблем качества данных содержится информация об изъянах, их статусе, критичности, ответственных сотрудниках и примечания отчётности. Директор по data governance и бизнес-аналитике Университета Британской Колумбии Джордж Фирикан написал информативный и краткий пост, в котором он приводит рекомендации по атрибутам, которые нужно включать в лог.
Ещё один аспект, который нужно рассмотреть и утвердить — это способ улучшения данных. Мы поговорим об этом в следующем разделе.
4. Реализация стандартов качества данных и управления данными
На этом этапе команда обеспечения качества данных реализует задокументированные ранее стандарты и процессы обеспечения качества данных для управления качеством данных на протяжении их жизненного цикла.
Команда может организовывать совещания, чтобы объяснять сотрудникам новые правила управления данными и/или для ознакомления с бизнес-глоссарием — документом с общей терминологией, одобренным высшим руководством и менеджерами.
Кроме того, члены команды обеспечения качества данных могут обучать сотрудников тому, как использовать универсальный или специализированный инструмент обеспечения качества данных для внесения исправлений.
5. Мониторинг и исправление данных
Очистка (исправление, подготовка) данных подразумевает удаление ошибочных или неполных записей в данных, их удаление или изменение. Существует множество способов подготовки данных: ручной, автоматический при помощи инструментов обеспечения качества данных, пакетная обработка при помощи скриптов, миграция данных или совместное использование этих способов.
Исправление данных включает в себя множество различных действий, в том числе:
- Анализ первопричин — выявление источника ошибочных данных, причин возникновения ошибок, изолирование факторов, влияющих на эту проблему, и поиск решения.
- Парсинг и стандартизация — сопоставление записей в таблицах баз данных с заданными паттернами, грамматикой и репрезентациями для выявления ошибочных значений данных или значений в ошибочных полях с последующим их форматированием. Например, аналитик качества данных может стандартизировать значения из разных систем измерения (фунты и килограммы), географические аббревиатуры записей (CA и US-CA).
- Сопоставление — выявление одинаковых или схожих сущностей в массиве данных и объединение их в одну. Сопоставление данных связано с решением проблемы подобия и связыванием записей. Можно использовать методику объединения массивов данных, после чего данные из нескольких источников интегрируются в одну конечную точку (процесс ETL). Решение проблемы подобия в массивах, содержащих записи об отдельных людях, позволяет создать единое описание клиента. При связывании записей обрабатываются записи, которые могут или не могут относиться к одному элементу (например, ключу базы данных, номеру социального страхования, URL) и которые могут отличаться из-за формата записей, места хранения, стиля или предпочтений куратора.
- Совершенствование — добавление новых данных из внутренних и внешних источников.
- Мониторинг — оценка данных с заданными интервалами для гарантии того, то они хорошо выполняют свои задачи.
А теперь нам нужно выяснить, какие специалисты определяют метрики и стандарты качества данных, кто оценивает данные, обучает сотрудников и кто реализует техническую сторону стратегии.
Команда обеспечения качества данных: роли и обязанности
Качество данных — это один из аспектов data governance, нацеленный на работу с данными таким образом, чтобы получить от них наибольшую выгоду. Руководителем высшего звена, отвечающим за использование данных и data governance на уровне компании, является chief data officer (CDO) (главный директор по обработке и анализу данных). CDO должен заниматься комплектацией команды обеспечения качества данных.
Количество ролей (должностей) в команде обеспечения качества данных зависит от размера компании, а следовательно и от объёма управляемых ею данных. В общем случае, в команде обеспечения качества данных работают специалисты с техническими и бизнес-знаниями. Возможные следующие варианты ролей:
Data owner (владелец данных) — контролирует качество конкретного массива или нескольких массивов данных, а также управляет им, задаёт требования к качеству данных. Владельцами данных обычно являются руководители высшего звена, отвечающую за бизнес-сторону команды.
Data consumer (потребитель данных) — обычный пользователь данных, задающий стандарты данных и сообщающий об ошибках членам команды.
Data producer — перехватывает данные, обеспечивая их соответствие требованиям потребителей данных к качеству.
Data steward — обычно отвечает за содержимое и контекст данных, а также за соответствующие бизнес-правила. Этот специалист обеспечивает соблюдение сотрудниками задокументированных стандартов и руководств по генерации данных и метаданных, доступу и использованию. Data steward также может давать рекомендации по совершенствованию имеющихся практик data governance и разделять ответственность с data custodian.
Data custodian — управляет технической средой обслуживания и хранения данных. Data custodian обеспечивает качество, целостность и безопасность данных в процессе ETL (extract, transform, load). Data custodian также называют data modeler, администратором баз данных (DBA) и ETL-разработчиком.
Data analyst (аналитик данных) — исследует, оценивает, обобщает данные и сообщает о результатах высшему руководству.
Так как аналитик данных — это одна из важнейших должностей в командах обеспечения качества данных, давайте рассмотрим её подробнее.
Аналитик качества данных: многозадачный специалист
Обязанности аналитика качества данных могут быть разнообразными. Этот специалист может выполнять задачи data consumer (потребителя данных), например, определение и документирование стандартов данных, поддержание качества данных до их загрузки в хранилище данных (обычно этим занимается data custodian). Согласно анализу вакансий, проведённому доцентом Университета Арканзаса в Литтл-Роке Элизабет Пирс, а также найденным нами описаниям должностей, в обязанности аналитика качества данных может входить следующее:
- Мониторинг и ревизия качества (точности, целостности) данных, вводимых пользователями в системы компании, извлекаемых, преобразуемых и загружаемых в хранилище данных
- Выявление первопричин проблем с данными и их устранение
- Измерение и отчёты руководству об результатах оценки качества данных и о выполняемых мерах по повышению качества данных
- Создание и контроль соглашений об уровне обслуживания, коммуникационных протоколов с поставщиками данных, политик и процедур по обеспечению качества данных
- Документирование экономического эффекта мероприятий по обеспечению качества данных.
Компании могут потребовать, чтобы аналитик качества данных организовывал и проводил обучение сотрудников по качеству данных, рекомендовал действия по улучшению данных. Также специалист может отвечать за обеспечение соответствия требованиям политики конфиденциальности данных компании.
Вы сами можете выбирать, как распределять обязанности в команде обеспечения качества данных. Однако в любой команде должен быть человек, управляющий всем процессом, выполняющий проверки качества, регулирующий правила обеспечения качества данных, разрабатывающий модели данных, а также технический специалист, поддерживающий поток и хранение данных во всей организации.
Инструменты обеспечения качества данных
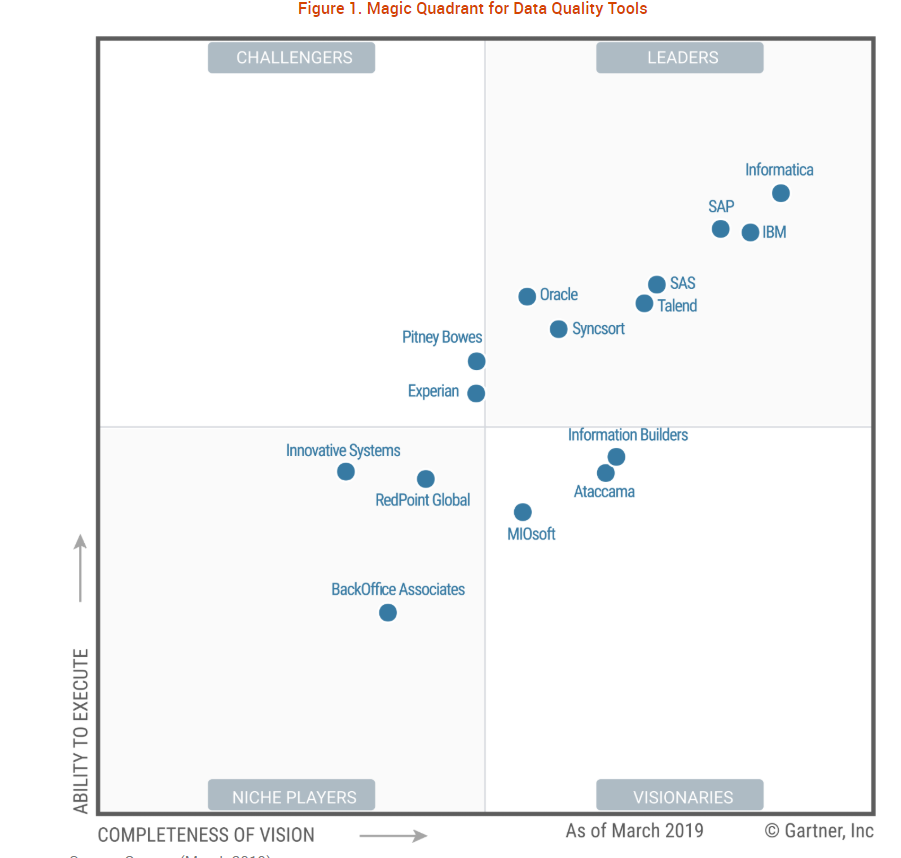
Стандартные инструменты обеспечения качества автоматизируют исправление данных и контроль качества благодаря таким функциям, как профилирование, сопоставление, управление метаданными и мониторинг. На рынке представлен широкий выбор таких инструментов. Gartner в своём Magic Quadrant for Data Quality Tools указывает 15 поставщиков, семь из которых являются лидерами. Давайте изучим различные решения, предлагаемые лучшими с точки зрения Gartner поставщиками.
IBM InfoSphere Information Server for Data Quality: сквозной инструмент для текущего мониторинга и очистки данных
IBM InfoSphere Information Server for Data Quality — один из четырёх продуктов обеспечения качества данных, предлагаемых компанией IBM. Он обеспечивает автоматизированный мониторинг данных и настраиваемую пакетную очистку в реальном времени. Решение выявляет изъяны в качестве данных и создаёт план их устранения на основании метрик, согласованных с бизнес-целями пользователя. То есть компании могут определять собственные правила качества данных.
Базовые функции инструмента включают в себя:
- Профилирование данных
- Преобразования для обеспечения качества данных: очистку, сопоставление, валидацию (например, гибкую конфигурацию таблицы на выходе для правил валидации данных, упорядочивание и анализ влияния)
- Настраиваемую стандартизацию данных (например, обогащение и очистку данных)
- Поддержку системы происхождения данных — пользователи могут видеть, какие изменения вносились в данные на протяжении их жизненного цикла
- Интеграцию данных
- Классификацию данных (например, выявление типа хранимых в столбце данных при помощи трёх десятков заданных настраиваемых классов данных)
- Оценку качества данных и очистку в рамках кластера Hadoop
Клиенты также могут воспользоваться лицензированием FlexPoint — получить гибкий доступ к IBM Unified Governance and Integration Platform.
Решение может быть развёрнуто на мощностях компании или в облаке. Цены предоставляются по заявке. IBM предоставляет информацию (электронные книги с видео и интерактивными демо), помогающую пользователям знакомиться с возможностями решения.
Informatica Data Quality: автоматизация управления качеством данных для машинного обучения и ИИ
Informatica Data Quality применяет подход к управлению качеством данных с использованием машинного обучения на основе метаданных. Одни из функций, на которые делает упор поставщик — гибкость инструмента с точки зрения рабочих нагрузок (веб-сервисов, реального времени, пакетной обработки и big data), роли пользователей (для различных бизнесов и ИТ), типы данных (транзакция, IoT, сторонняя, данные продукта или поставщика) и модели внедрения. В модели внедрения входят data governance, аналитика, управление основными данными, корпоративные озёра данных и так далее.
Другие ключевые функции Informatica Data Quality:
- Автоматизация критически важных задач обеспечения качества данных (восстановления данных) при помощи движка CLAIRE, использующего машинное обучение и другие методики ИИ
- Профилирование данных
- Преобразования для обеспечения качества данных: стандартизация, сопоставление, обогащение, валидация
- Интеграция данных
- Система создания правил для бизнес-аналитиков (создание и тестирование правил без помощи ИТ-сотрудников)
- Готовые стандартные бизнес-правила и акселераторы качества данных (то есть одно правило может использоваться в разных инструментах)
- Работа с исключениями (записями, не соответствующими условиям правил обеспечения качества данных).
Informatica Data Quality поддерживает публичные облачные сервисы (например, AWS и Microsoft Azure) и развёртывание на мощностях компании. Чтобы узнать стоимость, нужно связаться с поставщиком.
Trillium DQ: гибкая и масштабируемая платформа обеспечения качества данных для различных моделей использования
Trillium DQ — это пакет инструментов корпоративного класса для мониторинга качества данных и управления им. Это одно из шести решений для обеспечения качества данных компании Syncsort. Оно обеспечивает пакетную работу с качеством данных, но может и масштабироваться до применения в реальном времени, а также для работы с big data. Кроме того, Trillium DQ гибко работает с ролями пользователей, предоставляя функции самообслуживания для data steward, бизнес-аналитиков и других специалистов. Платформа поддерживает множество мероприятий, например, data governance, миграцию, управление основными данными, единое представление данных клиента, электронную коммерцию, распознавание мошенничества и так далее.
Основные функции Trillium DQ:
- Профилирование данных
- Готовые или настраиваемые преобразования для обеспечения качества данных: парсинг, стандартизация, валидация, сопоставление, обогащение данных
- Связывание данных
- Восстановление данных (для внутренних и внешних источников)
- Интеграция со специализированными и сторонними приложениями при помощи API с открытыми стандартами
- Интеграция с распределёнными архитектурами, например, с Hadoop и Spark, Microsoft Dynamics, SAP, сервисом Amazon EMR и любой гибридной средой для распределённых платформ
- Готовые формы отчётности и оценочных таблиц
Пользователи могут использовать продукт на собственных мощностях или в облаке. Информация о ценах предоставляется по заявке.
Также можно рассмотреть возможности других ведущих поставщиков наподобие Oracle, SAS, Talend, SAP и других, включённых в Magic Quadrant. Изучите данные на сайтах с отзывами пользователей, например, G2 или Capterra.
Спрос на подобные пакетные решения растёт, особенно с учётом огромного объёма данных, который генерируется ежедневно и должен быть гармонизирован. По данным Gartner, рынок программных инструментов для обеспечения качества данных в 2017 году достиг $ 1,61 миллиарда, что на 11,6 процентов больше, чем в 2016 году.
В заключение
Специалисты в этой области часто говорят, что стратегия управления качеством данных — это сочетание людей, процессов и инструментов. Когда люди разбираются с тем, что представляют собой высококачественные данные в их конкретной отрасли и организации, какие меры нужно предпринять, чтобы обеспечить возможность монетизации данных и какие инструменты могут поддерживать и автоматизировать такие меры и действия, проект принесёт желаемые результаты для бизнеса.
Размерности качества данных служат опорной точкой для создания правил обеспечения качества данных, метрик, моделей данных и стандартов, которые должны соблюдать все сотрудники с момента, когда они вводят запись в систему или извлекают массив данных из сторонних источников.