



Задача
Во-первых, давайте рассмотрим одну из таких задач. Исследователям OpenAI было нужно, чтобы, получив фрагмент текста и несколько вариантов его продолжения, живые разметчики подобрали то продолжение, которое лучше всего подходит к заданию, например, «какое продолжение имеет наиболее положительную эмоциональную окраску» или «какое продолжение является наиболее описательным».

Но вместо разметки этих данных большим пакетом, как мы делаем это обычно (офлайн), OpenAI хотела поместить свою модель в замкнутый цикл с нашими разметчиками, чтобы данные размечались онлайн: модель генерирует примеры текста, люди оценивают их при помощи нашего API, модель обучается на основе мнения людей, а затем процесс повторяется на протяжении нескольких дней.
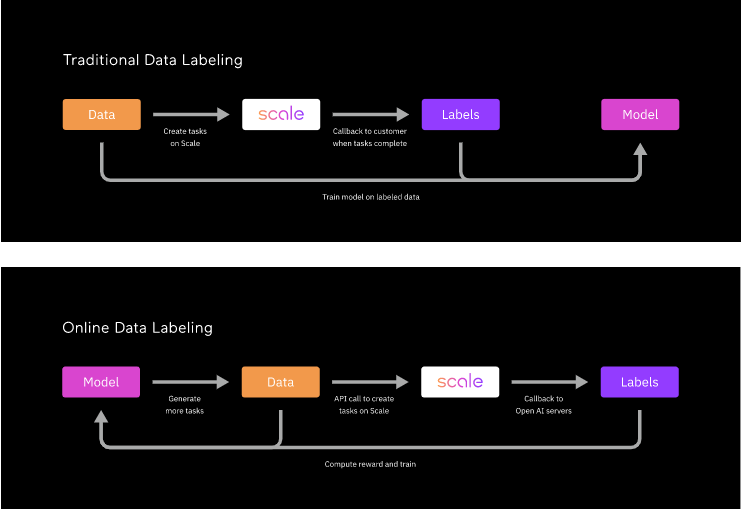
Это означало, что для того, чтобы эксперимент состоял из достаточного количества эпох и в то же время завершился быстро, задачи нужно было выполнять с очень низкой задержкой (менее чем за 30 минут) и с высокой производительностью (примерно пять тысяч меток в час). Как мы объясним ниже, эти ограничения были уникальными и потребовали от нас встраивания дополнительной функциональности в наш конвейер разметки данных.
Более того, ответы на эти задачи были ещё и крайне субъективными. Например, вот реальная задача, в которой надо выбрать наиболее описательное продолжение текста:

Из-за такой нечёткости сложно отличить людей, прилагающих реальные усилия, от людей (или ботов!) делающих случайные догадки. Однако чтобы масштабировать систему до тысяч разметчиков и в то же время предоставить заказчику качественные данные, нам нужно было реализовать это определение правильно.
Измерение качества в больших масштабах
Когда мы раньше создавали наш конвейер разметки, наши заказчики говорили нам отдавать приоритет высочайшему качеству данных, а не другим факторам, например, максимально быстрому полному циклу SLA. Теперь же нам нужно было придумать способ сохранения высокой планки качества параллельно с ускорением полного цикла с дней до минут.
Одной из причин повышения времени полного цикла была избыточность. В большинстве проектов мы пропускали каждую задачу через конвейер из множества людей, последовательно или параллельно. Обеспечение такой избыточности существенно снижает вероятность ошибок. Также она позволяет нам вычислять точность каждого сотрудника, сравнивая его ответы с завершённой версией задачи.
Ещё одной причиной медленного полного цикла были запаздывающие показатели качества. Обычно мы держали каждый пакет задач в состоянии подготовки, прежде чем передавать его заказчику, чтобы показатели уверенности разметчиков соответствовали новой информации. После чего мы могли повторно разметить задачи, уверенность в которых была низкой.
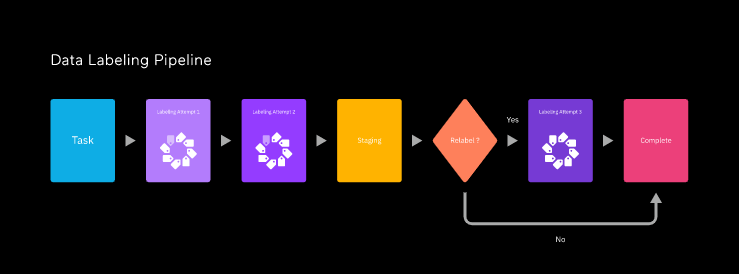
Однако из-за требований OpenAI к задержкам и производительности мы не могли бы использовать эти особенности в своей архитектуре — задачи должны были передаваться заказчику сразу после того, как их попытается решить один человек.
К счастью, проверка людьми работы других людей — это лишь один из способов определения качества разметчика. Например, в некоторых проектах computer vision одна из функций, определяющих качество разметчика, основана на показателе потери локализации от модели глубокого обучения.
Задачи-бенчмарки
Ещё один способ измерения качества заключался в использовании механизма под названием «задачи-бенчмарки». Основная идея состоит в том, чтобы сначала собирать ответы с высокой уверенностью для подмножества задач (называемого задачами-бенчмарками или золотым массивом данных в литературе), а затем использовать их для вычисления качества активных разметчиков. Задачи-бенчмарки распределяются по новым задачам, передаваемым исполнителям, и маскируются так, чтобы быть неотличимыми от них. Таким образом мы можем гарантировать, что не будем возвращать заказчику задачи от тех разметчиков, которые не соответствуют порогу качества в задачах-бенчмарках.
Мы успешно применяли задачи-бенчмарки как ещё один способ измерения качества, но обычно их вручную создавал наш внутренний отдел обеспечения качества. Такой ручной процесс не подошёл бы для этого проекта по нескольким причинам:
- мы хотели поддержать OpenAI в создании новых проектов и в быстрых итерациях экспериментов, не ограничивая скорость созданием бенчмарков командой Scale.
- из-за нечёткого характера задач было сложнее находить задачи, в ответах на которые у нас бы была высокая степень уверенности.
Чтобы решить эти проблемы, мы дополнили наш конвейер системой, автоматически выполняющей майнинг и обработку множества задач-бенчмарков.
После получения проекта наша система должна была выбирать из него небольшое подмножество задач, каждая из которых выполнялась несколькими надёжными разметчиками. Если почти все эти люди достигали консенсуса о правильности одного из ответов на задачу, то мы делали эту задачу бенчмарком, а этот ответ считался правильным. Использование большего количества рабочей силы допускалось только после получения достаточного количества бенчмарков.
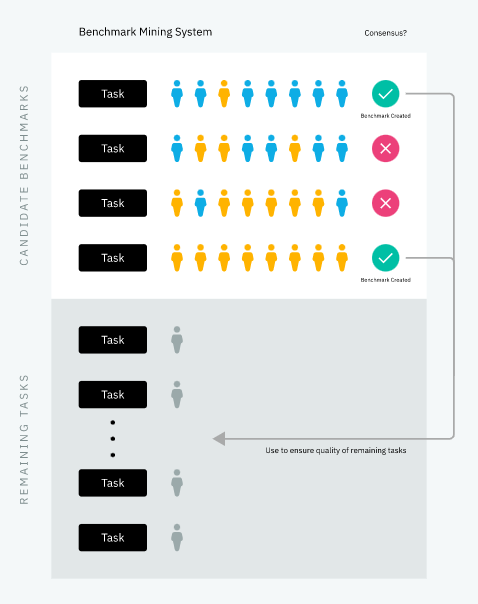
Чтобы повысить надёжность, к генерации бенчмарков допускались только сотрудники, имеющие наибольшую степень уверенности. Это согласуется с общим принципом, используемым нами при проектировании наших рабочих систем: *использовать людей, которым мы доверяем больше всего*. Если над созданием бенчмарков работают самые точные разметчики, то их работу можно использовать в дальнейшем для оценки работы гораздо большего количества людей.
Так как мы выбираем задачи, в которых был достигнут консенсус, стать бенчмарком больше шансов у недвусмысленных задач, чем у нечётких. В каком-то смысле это полезно, потому что мы можем быть уверены в том, что наша оценка качества имеет малую степень шума. Однако сложность этого в том, что такое множество задач-бенчмарков больше не является репрезентативным для исходного множества задач.
В данном конкретном случае это нас устраивало, поскольку мы надеялись избавиться от злонамеренных и неквалифицированных разметчиков, в то же время оставляя пространство для человеческих предпочтений и субъективности. У нас часто возникала потребность в понимании связи между сложностью тестовых вопросов и ложноположительных/ложноотрицательных ответов, которую подробно изучают области наподобие современной теории тестирования (Item Response Theory).
Организуем работу
При наличии сложной системы, включающей в себя обладающих непредсказуемым поведением акторов со свободой воли (живых разметчиков), каждая новая функция требует множественных итераций — циклов внедрения изменений, наблюдений за реакцией системы на них с последующей реакцией на новые тенденции. Система генерации бенчмарков не является исключением. В статье мы рассмотрим два из множества внесённых нами улучшений.
Динамическая передача
Как в любой другой работе, качество даже самых хороших разметчиков может быть непостоянным. Изначально мы распределяли задачи-бенчмарки с постоянной равномерной частотой выборки, то есть для надёжной оценки качества конкретного разметчика системе требовалось долгое время. Мы улучшили логику передачи задач-бенчмарков, её частота начала меняться динамически; в случае подозрений на снижение качества разметчику отправлялось больше бенчмарков.
Предотвращение эвристик и перекоса
Всё работало хорошо, пока мы не добрались до проекта определения описательности, в котором разметчикам нужно было выбирать наиболее описательное продолжение из четырёх вариантов. Наш аудит качества выявил снижение показателей, подтверждённое тем, что среднее время, которое разметчики тратили на эти задачи, тоже начало падать.
Что же необычного было в этом проекте?
Оказалось, что правильный ответ (наиболее описательный вариант) имел также чрезвычайно высокую вероятность оказаться самым длинным. Часто это было достаточно верно для того, чтобы стратегия «выбирай самый длинный вариант» позволяла оставаться в пределах допустимого качества и оказывалась гораздо более выгодной, чем честная работа.
И это демонстрирует необходимость внимания к распределению задач-бенчмарков. Явным образом добавив примеры, направленные против перекосов, и изменив их веса (в данном случае это примеры, в которых самый длинный вариант не является правильным) в наборе наших бенчмарков, мы смогли выполнить коррекцию с учётом этой проблемы.
Примечание по тестированию и мониторингу
Каждая распределённая система требует тестирования и тщательного мониторинга, и наша распределённая система с участием людей — не исключение.
Как нам тестировать изменения в системе, зависящей от непредсказуемого поведения людей? Наша компания обычно тестирует подобные аспекты, запуская «синтетические проекты» — версии-песочницы реальных проектов, которые мы выполняли ранее, с составом разметчиков, схожим с составом в реальном проекте. Это позволяет нам экспериментировать и быстро выполнять итерации без риска испортить конвейер разметки при работе с заказчиком. Мы использовали синтетические проекты для настройки параметров и проверки гипотез, а однажды даже «подогревали» наших сотрудников, давая им задачи, которые они выполняли, пока мы ждали новых задач от заказчика.
Кроме того, нам нужно выполнять мониторинг системы и качество на выходе, чтобы гарантировать отсутствие регрессий. Именно благодаря этому мы быстро выявили некоторые из описанных выше проблем, а затем отреагировали на них. Мы настроили систему уведомлений, сообщающую о том, что уровень согласования между разметчиками, производительность или среднее время на задачу выходят за пределы интервала ожидаемых значений.
Кроме автоматизированных уведомлений нам требуется постоянный количественный мониторинг всех наших проектов, который выполняется внутренним отделом обеспечения качества. В этом аспекте проект OpenAI ничем не отличался. Для проверки этой системы мы настроили процесс аудита разметчиков, которые, судя по бенчмаркам, были близки к нашему порогу фильтрации. Это позволяло им уведомлять нас, если система ошибочно отфильтровывала хорошо работающих разметчиков (ложноположительные срабатывания) или не отфильтровывала разметчиков с недостаточным качеством (ложноотрицательные срабатывания).
Наконец, поскольку у нас был доступ к небольшой выборке данных, размеченной самими исследователями OpenAI, мы настроили ежедневный cron в нашей асинхронной службе задач, который давал нашим сотрудникам задание повторно размечать эту выборку и уведомлял нас, если качество было ниже требуемого.
Что дальше
После изготовления прототипа этой системы и его анализа мы внедрили его во все проекты обработки естественного языка и категоризации, а также в наш конвейер computer vision. Также мы повысили точность нашего классификатора, который при помощи байесовской модели определяет качество разметчиков.