


На мой взгляд, статья Янна Лекуна с соавторами Backpropagation Applied to Handwritten Zip Code Recognition (1989 год) имеет определённую историческую ценность, поскольку, насколько мне известно, это первое реальное применение нейронной сети, от начала до конца обученной при помощи обратного распространения (backpropagation). Если не учитывать крошечный датасет (7291 изображений цифр в градациях серого размером 16x16) и крошечный размер использованной нейронной сети (всего тысяча нейронов), эта статья спустя 33 года ощущается вполне современной — в ней описана структура датасета, архитектура нейронной сети, функция потерь, оптимизация и приведены отчёты об величинах экспериментальных ошибок классификации для обучающего и тестового датасетов. Всё это очень узнаваемо и воспринимается как современная статья о Deep Learning, только написанная 33 года назад. Я решил воспроизвести эту статью 1) для развлечения, а ещё 2) чтобы использовать это упражнение как исследование природы прогресса глубокого обучения.
Реализация
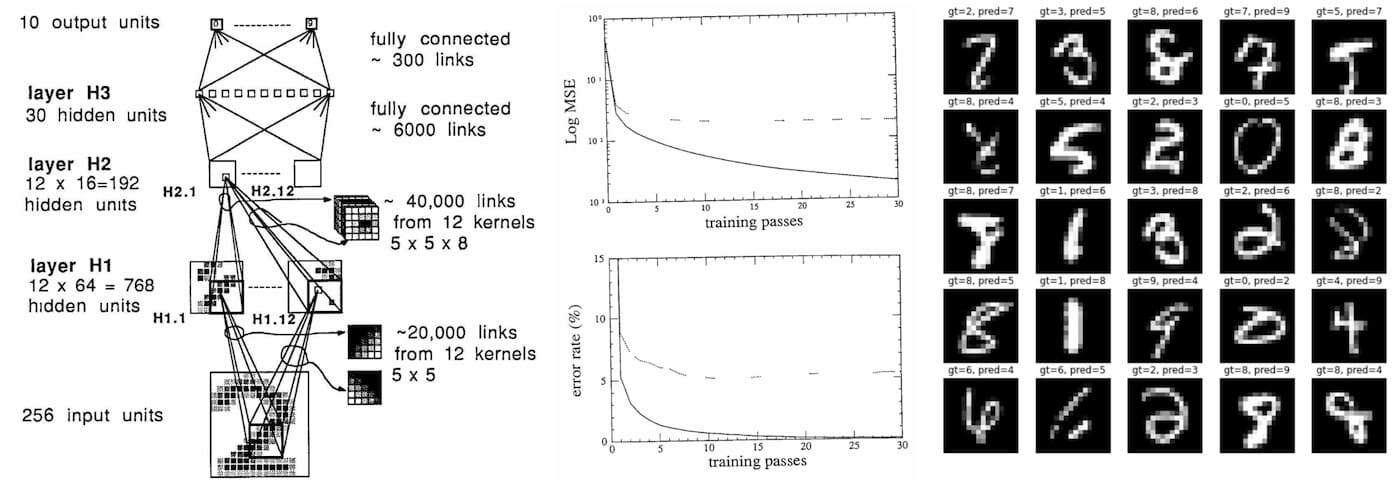
Я стремился максимально близко воссоздать статью и повторно воссоздал всё на PyTorch в github-репозитории karpathy/lecun1989-repro. Исходная сеть была реализована на Lisp при помощи симулятора обратного распространения SN 1988 года Ботту и Лекуна (позже названного Lush). Статья написана на французском, поэтому мне она не очень понятна, но по синтаксису похоже, что можно описывать нейронные сети при помощи высокоуровневого API, аналогично тому, как это сегодня делается с PyTorch. Краткое примечание об архитектуре ПО: современные библиотеки позволили реализовать архитектуру, разделённую на три компонента: 1) быстрая общая тензорная библиотека (C/CUDA), реализующая базовые математические операции с многомерными тензорами; 2) autograd-движок, отслеживающий граф вычислений прямого распространения и способный генерировать операции для обратного прохода; 3) скриптовый (Python) высокоуровневый API стандартных операций глубокого обучения, слоёв, архитектур, оптимизаторов, функций потерь и так далее.
Обучение
В процессе обучения мы выполним 23 прохода по обучающему датасету из 7291 примеров, получив суммарно 167693 представлений (пример, метка) для нейронной сети. Сеть из оригинала статьи обучалась три дня на рабочей станции SUN-4/260. Я запустил свою реализацию на MacBook Air (M1), который обработал её примерно за 90 секунд (наивное ускорение примерно в 3000 раз). Моя conda настроена на использование нативных сборок arm64 вместо эмуляции Rosetta. Ускорение могло быть ещё больше, если бы у PyTorch имелась поддержка всей функциональности M1 (в том числе GPU и NPU), но, похоже, она находится в процессе разработки. Также я попробовал просто запустить код на GPU A100, но обучение оказалось медленнее; скорее всего, это вызвано тем, что сеть крошечная (четырёхслойная свёрточная сеть максимум с 12 каналами, 9760 параметрами, 64 тысячами MAC, 1 тысячей активаций), поэтому SGD использует за раз только один пример. Однако если бы кто-то захотел решать эту задачу на современном оборудовании (A100) и программной архитектуре (CUDA, PyTorch), нам нужно было бы заменить SGD для каждого примера на полнобатчевое обучение, чтобы максимизировать использование GPU; при этом, скорее всего, мы достигли бы ускорения обучения ещё примерно в сто раз.
Воссоздание показателей 1989 года
В статье указаны следующие результаты:

А мой обучающий скрипт repro.py в его текущем виде выводит в конце 23-го прохода следующее:

То есть я воспроизвожу значения приблизительно, а не точно. К сожалению, точное воспроизведение, скорее всего, невозможно, поскольку исходный датасет был со временем утерян. Поэтому мне пришлось симулировать его при помощи более крупного датасета MNIST (никогда не думал, что скажу такое), взяв его цифры размером 28x28, уменьшив их до 16x16 пикселей билинейной интерполяцией и случайно без замены выбрав нужное количество примеров для обучающего и тестового датасетов. Но я уверен, что повлияли и другие помехи. Например, в статье слишком абстрактно описывается схема инициализации весов; к тому же я подозреваю, что в файле pdf есть погрешности форматирования: например, в нём удаляются точки ".", из-за чего «2.5» выглядит как «2 5» и, возможно, удаляются квадратные корни. Например, если нам сообщают, что инициализация весов берётся из равномерного «2 4 / F», где F — это нагрузочный коэффициент по входу, я думаю, что это точно (?) означает «2.4 / sqrt(F)», где sqrt помогает сохранить среднеквадратичное отклонение выводов. Описание разреженной структуры связи между слоями H1 и H2 тоже размыто, в статье просто говорится, что она «выбрана согласно схеме, рассматривать которую мы здесь не будем», поэтому мне пришлось самому логически догадываться о разреженной структуре пересекающихся блоков. В статье также заявляется об использовании нелинейности tanh, но я опасаюсь, что на самом деле это был «нормализованный tanh», отображающий ntanh(1) = 1, и, потенциально, с добавленным уменьшенным skip connection; в то время это использовалось для обеспечения хотя бы небольшого градиента в плоских хвостах tanh. Наконец, в статье используется «особая версия алгоритма Ньютона, применяющего положительную диагональную аппроксимацию гессиана», но я использовал только SGD, потому что это намного проще; к тому же, в статье ещё говорится следующее: «мы не считаем, что этот алгоритм обеспечивает огромный рост скорости обучения».
Жульничество с путешествием во времени
Это моя любимая часть. Мы живём на 33 года вперёд в будущем, где глубокое обучение стало очень активной областью исследований. Насколько мы сможем улучшить исходный результат благодаря современному пониманию и 33 годами исследований и разработок? Мой исходный результат был таким:

Первым делом мне показалось подозрительным, что мы выполняем простую классификацию на десять категорий, но во время написания статьи это моделировалось как регрессия среднеквадратичной погрешности (MSE) в целевые значения -1 (для отрицательного класса) или +1 (для положительного класса), а выходные нейроны тоже имели нелинейность tanh. Поэтому я удалил tanh в выходных слоях, чтобы получить логиты классов, и подставил стандартную (многоклассовую) функцию потерь перекрёстной энтропии. Это изменение существенно снизило погрешность обучения, полностью переобучив обучающий датасет:

Подозреваю, что нужно быть гораздо более аккуратным с подробностями инициализации весов, если выходной слой имеет (насыщающую) нелинейность tanh, и поверх неё среднеквадратичную погрешность. Во-вторых, по моему опыту, очень тщательно настроенный SGD может работать крайне хорошо, однако современный оптимизатор Adam (разумеется, со скоростью обучения 3e-4) почти всегда является надёжным базовым решением и почти не требует или вообще не требует подстройки. Поэтому чтобы ещё больше убедиться, что оптимизация не препятствует точности, я перешёл на AdamW с LR 3e-4 и на протяжении обучения снижал скорость до 1e-4, что дало мне следующее:

Это дало чуть улучшенный результат поверх SGD, только нам также нужно помнить, что мы привнесли небольшое уменьшение весов, вызванное стандартными параметрами, что помогает справляться с проблемой переобучения. Так как у нас по-прежнему присутствует сильное переобучение, далее я внедрил простую стратегию аугментации данных, сдвинув входные изображения на 1 пиксель по горизонтали или вертикали. Однако поскольку это симулирует увеличение объёма датасета, мне также пришлось увеличить количество проходов с 23 до 60 (я проверил, что простое наивное увеличение проходов в исходных условиях не улучшало существенно результаты):

Как видно из погрешности тестирования, это достаточно сильно помогло! Аугментация данных — довольно простая и очень стандартная концепция, используемая для устранения переобучения, однако я не встретил её упоминания в статье 1989 года; возможно, это была более недавняя инновация (?). Так как у нас всё равно присутствует небольшое переобучение, я воспользовался ещё одним современным инструментом: dropout. Я добавил небольшой дропаут с величиной 0.25 непосредственно перед слоем с наибольшим количеством параметров (H3). Так как дропаут обнуляет активации, не имеет особого смысла использовать его с tanh, имеющим активный диапазон [-1,1], поэтому я заменил все нелинейности гораздо более простой функцией активации ReLU. Так как дропаут добавляет во время обучения ещё больше шума, нам также нужно выполнять обучение дольше, увеличив количество проходов до 80, что даёт нам следующее:

Это снижает количество ошибок в тестовом датасете всего до 32 / 2007! Я удостоверился, что простая замена tanh -> relu в исходной сети не даёт существенного выигрыша, то есть основной причиной улучшения здесь стало добавление дропаута. Подведём итог: если бы я отправился на машине времени в 1989 год, то смог быть снизить частоту ошибок примерно на 60%, снизив их количество примерно с 80 до примерно 30 и получив общую частоту ошибок на тестовом датасете примерно 1,5%. Однако этот выигрыш даётся не бесплатно: мы почти в четыре раза увеличили время обучения, что в 1989 году дало вместо трёх дней обучения почти двенадцать. Однако на задержку инференса это бы не повлияло. Оставшиеся ошибки показаны на рисунке:

Двигаемся дальше
Однако после замены MSE -> Softmax, SGD -> AdamW, добавления аугментации данных, дропаута и замены tanh -> relu у меня начали заканчиваться простые идеи. Я проверил ещё несколько идей (например, нормализацию весов), но не получил существенно лучших результатов. Также я попытался миниатюризировать Visual Transformer (ViT) в «micro-ViT», который приблизительно соответствовал по количеству параметров и арифметических операций, однако не смог достичь точности свёрточной сети. Разумеется, за последние 33 года появилось множество других инноваций, однако многие из них (например, остаточные соединения, нормализации слоёв/батчей) стали релевантными только в гораздо более крупных моделях и в основном помогают в стабилизации крупномасштабной оптимизации. На этом этапе дальнейшие улучшения могут быть вызваны увеличением масштаба сети, однако это сильно увеличит величину задержки инференса времени тестирования.
Жульничество с данными
Ещё один способ повышения точности мог бы заключаться в увеличении размеров датасета, однако для этого нужно было бы потратить деньги на разметку. Для сравнения: наш исходный базовый результат для воспроизведения выглядел так:

Воспользовавшись тем, что в нашем распоряжении есть целый MNIST, мы можем просто попробовать увеличить обучающий датасет приблизительно в семь раз (с 7291 до 50000 примеров). Выполнение обучения исходной модели в течение 100 проходов уже демонстрирует некоторые улучшения благодаря одному только добавлению данных:

Однако дальнейшее комбинирование увеличения количества данных с современными инновациями (описанными в предыдущем разделе) даёт нам наилучшую точность:

Подводя итог, можно сказать, что простое увеличение датасета в 1989 году стало бы эффективным способом повышения точности системы, за который бы не пришлось расплачиваться увеличением задержек инференса.
Выводы
Давайте подведём итог тому, чему мы научились как путешественник во времени из 2022 года, исследующий передовые на 1989 год технологии глубокого обучения:
- Во-первых, на макроуровне за 33 года изменилось не очень много. Мы по-прежнему создаём дифференцируемые архитектуры нейронных сетей, составленные из слоёв нейронов, и оптимизируем их от начала до конца при помощи обратного распространения и стохастического градиентного спуска. Всё кажется очень знакомым, только очень маленьким.
- Датасет по современным стандартам просто детский: обучающий набор состоит всего из 7291 изображения в градациях серого размером 16x16. Современные датасеты компьютерного зрения обычно содержат несколько сотен миллионов цветных изображений высокого разрешения из веба (например, у Google есть JFT-300M, а OpenAI CLIP обучался на четырёхсот миллионах), но разрастаются уже до нескольких миллиардов. Это примерно в тысячу раз увеличивает объём пиксельной информации на изображение (384*384*3/(16*16)) и примерно в сто тысяч раз увеличивает количество изображений (1e9/1e4), что даёт на входе в сто миллиардов раз больше пиксельных данных.
- Нейронная сеть тоже крошечная: эта сеть 1989 года имеет примерно 9760 параметров, 64 тысяч MAC и 1 тысячу активаций. Современные нейронные сети (компьютерного зрения) имеют масштабы нескольких миллиардов параметров (в миллион раз больше) и O(~1e12) MAC ( в десять миллионов раз больше). Модели естественного языка могут достигать триллионов параметров.
- Передовой классификатор, обучение которого на рабочей станции занимало три дня, теперь обучается на моём ноутбуке без вентилятора за 90 секунд (наивное ускорение в три тысячи раз), и с большой вероятностью скорость можно увеличить ещё примерно в сто раз благодаря переключению на полнобатчевую оптимизацию и использование GPU.
- На самом деле, я смог настроить модель, аугментацию, функцию потерь и оптимизацию на основании современных инноваций, чтобы снизить уровень ошибок на 60% без изменения датасета и задержки времени тестирования модели.
- Приличное улучшение оказалось достижимо благодаря только одному увеличению масштаба датасета.
- Ещё более существенных улучшений, вероятно, можно добиться увеличением модели, что потребует больше вычислительных ресурсов, и дополнительными исследованиями, помогающими стабилизировать обучение при увеличивающихся масштабах. В частности, если бы я перенёсся в 1989 год, то в конечном итоге упёрся бы в ограничение возможностей улучшения системы без более мощного компьютера.
Предположим, что выводы, сделанные из этого упражнения, останутся неизменными во времени. Что же это скажет нам о глубоком обучении в 2022 году? Что путешественник во времени из 2055 года подумал бы о показателях современных сетей?
- На макроуровне нейронные сети 2055 года, по сути, будут теми же сетями 2022 года, только больше размером.
- Сегодняшние датасеты и модели выглядят насмешкой. И те, и другие станут приблизительно в десять миллионов раз больше.
- Можно будет обучить передовые модели 2022 года примерно за одну минуту, выполняя наивное обучение на личном вычислительном устройстве в качестве хобби-проекта на выходные.
- Современные модели сформулированы неоптимально, и простое изменение отдельных деталей модели, функций потерь, аугментации или оптимизатора способно уменьшить ошибки примерно вдвое.
- Наши датасеты слишком малы, и приличное улучшение можно получить увеличением масштаба одного только датасета.
- Однако дальнейшие усовершенствования невозможны без расширения компьютерной инфраструктуры и инвестиций в исследования и разработки по эффективному обучению моделей такого масштаба.
Однако самый важный тренд, о котором бы я хотел сказать — это то, что вся ситуация с обучением нейронной сети с нуля на какую-то целевую задачу (например, распознавание цифр) быстро становится устаревшей из-за тонкой настройки (finetuning), особенно с появлением базисных моделей (foundation model) наподобие GPT. Эти базисные модели обучаются лишь несколькими организациями, имеющими существенные вычислительные ресурсы, а применение в большинстве сфер достигается легковесной тонкой настройкой части сети, инжинирингу промптов или дополнительным этапом дистилляции данных или модели в более мелкие специализированные сети инференса. Я считаю, что этот тренд продолжит существовать и на самом деле усилится. В наиболее экстремальной интерполяции нам вообще не понадобится обучать никаких нейронных сетей. В 2055 году мы будем просить выросший в десять миллионов раз мегамозг нейронной сети выполнить какую-нибудь задачу, проговорив (или подумав) её на родном языке. И если вы попросите достаточно вежливо, он подчинится. Да, вы по-прежнему сможете обучать нейронные сети… но зачем это будет нужно?