



Чтобы создать модель машинного обучения для классификации постов по таким категориям, необходимо получить высококачественные размеченные данные обучения. Иными словами, нам нужны примеры постов в социальных сетях, которые вручную размечены как пресс-релизы или обзоры пользователей, чтобы модель могла учиться тому, как распознавать новые примеры того же типа.
К сожалению, разметка вручную — это трудная и медленная задача. Более того, она может быть дорогой, если выполняется командой разработчиков машинного обучения или требует знаний специалистов в области. Одно из решений заключается в краудсорсинге, но это влечёт за собой дополнительные затраты на управление данными, чтобы гарантировать надёжность разметчиков. С такими задачами могут справляться сторонние сервисы разметки, однако это привносит другие сложности, например, утерю прозрачности процесса разметки, замедление оборота данных и необходимость решения проблемы ограничений использования конфиденциальных данных. Время оборота и трудозатрат на разметку данных становятся особо серьёзными проблемами на ранних этапах проекта; в фазе формирования проекта всё часто меняется, а разметчикам нужны чётко сформулированные инструкции, а не расплывчатые эвристики. Смена целей может повлиять на ранее размеченные данные, из-за чего работу приходится начинать заново с нуля. Процесс исследований и разработки становится чрезвычайно медленным.
К счастью, последние открытия в области NLP снизили эту потребность в размеченных данных для обучения. Сегодня уже привычно предварительно обучать модели так, чтобы они учились заполнять пробелы в предложениях словами. Такая задача моделирования языка не требует ручной разметки и позволяет нам создавать модели, преобразующие входящий текст в обогащённый вид с учётом контекста. Потом такое описание можно использовать в качестве входящих данных нашей более конкретной задачи. Это снижает потребность в данных для обучения, потому что модель уже многое узнала о том, как работает язык и даже имеет простейшее понимание мира. Например, подобные модели способны правильно завершить предложение вида «Поезд подошёл к ...» словом «станции», поэтому хотя бы на очень поверхностном уровне можно сказать, что они знают кое-что о железнодорожном транспорте.
Хотя эти языковые модели снижают потребность в ручной разметке, чтобы обучить модель для конечной задачи, всё равно требуются высококачественные размеченные данные. В этом посте мы продемонстрируем, как использовали обучение со слабым контролем для обеспечения быстрых итераций в разработке продукта и расскажем о последующем влиянии применения слабого контроля в нашем рабочем процессе.
Обучение со слабым контролем спешит на помощь
Термин «обучение со слабым контролем» (weak supervision) подразумевает обучение моделей машинного обучения только с помощью шумных меток вместо «золотого» массива данных, уверенность в котором высока. Такие шумные, или слабые, метки, обычно гораздо проще получить, чем золотую разметку, и в определённых условиях их можно использовать для обучения высокопроизводительных моделей машинного обучения.
Фреймворк Snorkel обеспечивает систему программируемой разметки. В ней шумные метки создаются при помощи понятных эвристик, получаемых благодаря знанию предметной области данных. Например, если пост в соцсети содержит слово «обзор», то он вполне может быть пользовательским обзором. Это хорошее эмпирическое правило, однако может существовать множество случаев, в которых это слово используется, но пост заключается в чём-то совершенно другом, поэтому результаты разметки будут шумными. На практике эта эвристика применяется коротким фрагментом кода, называемым функцией разметки (labeling function, LF). Она получает пост и возвращает метку, или сообщает, что она не уверена в ответе, отказываясь возвращать метку. В этом примере она может вернуть положительный результат, если встретит слово «обзор» или сообщить о своей неуверенности в противном случае. Другие LF могут обрабатывать отрицательные случаи и назначать отрицательную метку или сообщать о неуверенности.
Единственная функция разметки создавала бы очень шумные результаты, поэтому используется множество разных функций, а результаты их работы комбинируются для создания общей метки при их согласовании; оно может быть реализовано простым мажоритарным голосованием или другими, более сложными способами. Затем эти готовые слабые метки используются для обучающих/валидирующих и тестовых массивов данных, после чего классификатор машинного обучения обучается обычным образом.
Функции разметки могут быть довольно мощными и обеспечивать множество преимуществ. Задумайтесь на минуту о различиях масштабируемости двух подходов: ручного присваивания метки одной точке данных и написания LF, присваивающей метки большим частям обучающего массива данных. Кроме того, присвоенные метки можно улучшить при помощи процедуры активного обучения; человек может вручную исследовать примеры данных, в которых обученная модель в своём предсказательном распределении имеет высокую степень неуверенности, и написать новые LF, учитывающие эти случаи.
Так как функции разметки не добавляют метку, если они слишком не уверены, есть вероятность, что набор LF сможет разметить только часть всего пространства данных. На рисунке 1 показана ситуация, в которой заданы четыре LF; две из них генерируют положительные метки, а две другие — отрицательные метки. Для контролируемого обучения будут применимы только данные, находящиеся в областях, покрытых LF. Однако можно обучить модель, выполняющую обобщение за пределы этих областей благодаря методикам регуляризации и способности процедур обучения использовать признаки данных, не учитываемые LF.

Рисунок 1: Истинное многообразие положительного класса задачи двоичной классификации показано синим. Задано четыре слабых разметчика с ограниченным покрытием: границы их решений показаны жёлтым/серым, что соответствует присвоению положительных/отрицательных меток. Слабая метка присваивается только подмножеству точек данных, попадающему в эти области, поэтому только его можно использовать для обучения модели. Справа граница решений обученной модели показывает, как может проявляться обобщение за пределы покрытия LF.
Ещё одно преимущество LF заключается в том, что их легко понимать и модифицировать. С внезапным изменением определения класса можно справиться при помощи аудита кода LF, который в дальнейшем можно изменить в соответствии с новым определением (см. рисунок 2).
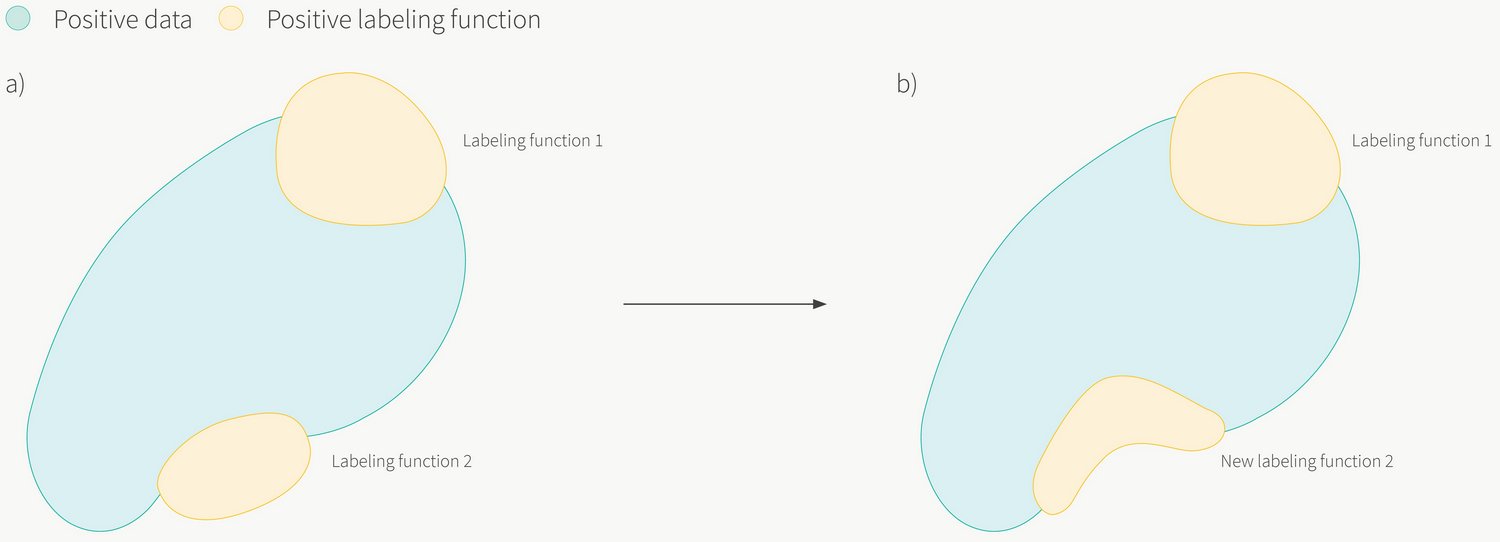
Рисунок 2: a) Программная разметка позволяет нам быстро адаптироваться к меняющимся требованиям. При изменении определения класса (то есть при изменении положительной синей области) мы обнаруживаем, что LF2 стала неадекватной; она размечает как положительные множество примеров за пределами синей области. b) В таком случае мы можем просто изменить исходный код LF2 и пересчитать все слабые метки.
Конечным результатом применения программной разметки является прозрачный и детерминированный конвейер, преобразующий подаваемые на вход сырые, неразмеченные данные в полностью обученную модель машинного обучения, которую можно внедрять в продакшен. В нашем случае применение этого фреймворка обучения со слабым контролем к задачам классификации больших текстов помогло нам снизить время разработки модели с недель до считанных дней. Оно позволило ускорить итерации с конечными пользователями, что улучшило цикл разработки продукта в целом. Также оно обеспечило возможность валидации многих идей, которым в случаях, когда требовалась ручная разметка, никогда не отдавался приоритет из-за плохого соотношения между риском и выигрышем.
Новые сигналы мониторинга без лишних затрат
При внедрении нашей обученной модели в продакшен мы столкнулись со вторым интересным способом применения функций разметки: можно использовать набор LF для мониторинга точности модели. Это было особенно интересно потому, что мы имели дело с реальными потоками текстовых данных. Опасности сдвига предметной области (при котором меняется распределение входящих данных) и сдвига концепции (при котором меняется соотношение между входящими данными и метками) очень серьёзны и быстрое распознавание этих явлений представляет собой сложную задачу.
Покрытие функций разметки отличается от покрытия обученной модели, и мы можем использовать этот факт, чтобы создать систему, чувствительную к таким явлениям в реальном распределении данных. Обычно мы ожидаем, что ежедневно будет выявляться определённое количество расхождений между прогнозами модели и прогнозами LF. Мы называем их «несоответствиями». При изучении общей статистики, например, ежедневного количества несоответствий, создаётся мощный сигнал временной последовательности, в котором отклонение от нормы является показателем проблем в системе. В такой схеме LF действуют подобно «датчикам задымлённости», включающим тревогу, когда возникает изменение в той части распределения данных, которую они должны фиксировать. Эта идея проиллюстрирована на рисунке 3.
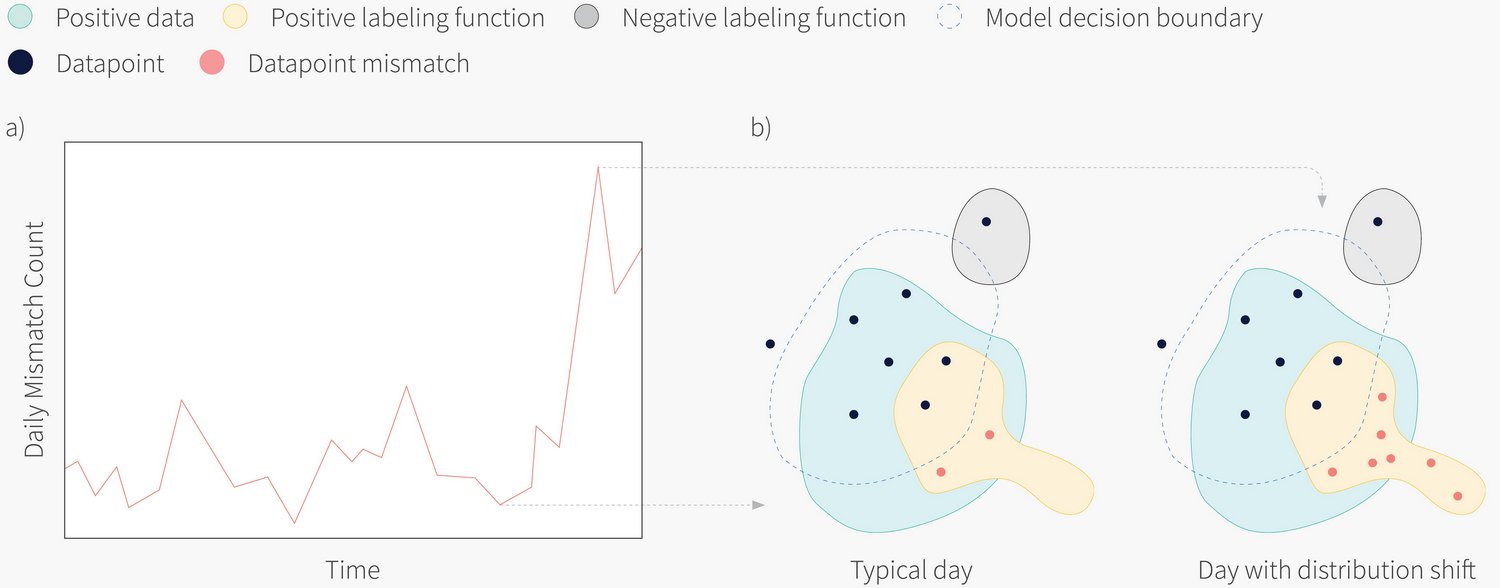
Рисунок 3: a) Временная последовательность количества несоответствий между результатами работы функции разметки и модели. b) Сдвиг в распределении входящих данных может вызвать дополнительные несоответствия, что приводит к изменению их ожидаемого количества. Когда во временных последовательностях выявляются такие аномалии, соответствующим ответственным лицам отправляются уведомления.
Дополнительное преимущество такой системы заключается в том, что LF обычно содержат в себе некие знания предметной области о данных. Создание сигнала временной последовательности для каждой LF позволяет нам связать их аномалии с аспектом данных, для которого они были написаны. В одном случае мы мониторили фильтры шума, используемые для очистки потока данных, состоявшего из новостей о биотехнологической организации. Спустя несколько месяцев мы заметили большой скачок в ежедневном количестве несоответствий. После тщательного исследования мы выяснили, что одна из LF помечала соответствующие фрагменты текста как шум из-за запутывающей аббревиатуры, появившейся в результатах недавних испытаний компании. Ещё больше таких примеров появилось после внедрения системы. В общем случае мы выяснили, что наличие такого уровня интерпретируемости срабатывало наилучшим образом, когда LF имели высокую степень точности, поэтому не все LF напрямую преобразовывались в сигналы мониторинга; многие были переработаны, чтобы иметь меньше покрытие, но более высокую точность.
Такая система мониторинга позволила нам вставлять автоматизированные проверки на адекватность точности внедрённой модели. Поэтому она играла важную роль в обеспечении нашей уверенности в точности системы и преобразовывала уведомления в задачи, в которых команда часто выявляла области распределений данных, обрабатывать которые наша внедрённая модель умела не так хорошо. Выявленные проблемы устранялись написанием новых или модификацией старых LF и выполнением полного переобучения.
Заключение: сложности функций разметки и необходимость креативности
Написание хороших функций разметки — это не наука, а искусство. Каждая задача имеет собственные особенности и сложности, которые могут сильно повлиять на простоту написания LF. Мы обнаружили, что благодаря тому, как текстовые данные анализируются в коде, для обработки фреймворком Snorkel особенно хорошо подходят задачи из NLP (например, очень легко кодировать LF на основе ключевых слов), и этим в большой степени может быть вызван успех его применения в наших случаях.
Как бы то ни было, решение сложностей разметки — фундаментальная часть управления данными и разработки ML-систем. Мы ощутили на себе преимущества, обеспечиваемые программной разметкой, что мотивировало нас на поиск способов написания LF для различных типов неразмеченных данных. Как ни удивительно, наша история не так уж необычна. Интересно будет посмотреть, окажутся эти инструменты ли в конечном итоге доступными бизнес-пользователям, что упростит внедрение машинного обучения в новых предметных областях и сферах применения.