



Данные — один из самых ценных в наше время ресурсов. Однако из-за затрат, конфиденциальности и времени обработки сбор реальных данных не всегда возможен. В таком случае для подготовки моделей машинного обучения хорошей альтернативой могут стать синтетические данные. В этой статье мы объясним, что такое синтетические данные, почему они используются и когда их лучше применять, какие существуют модели и инструменты генерации и какими способами можно задействовать синтетические данные.
Что такое синтетические данные?
Синтетические данные — это искусственные данные, имитирующие наблюдения реального мира и используемые для подготовки моделей машинного обучения, когда получение реальных данных невозможно из-за сложности или дороговизны. Синтетические данные отличаются от аугментированных (augmented) и рандомизированных данных. Давайте продемонстрируем отличие синтетических данных от других методик на крайне упрощённом примере генерации человеческих лиц. Представьте, что у вас есть датасет фотографий реальных людей.
Аугментирование данных, по сути, является процессом добавления к датасету слегка изменённых копий существующих элементов. Применение аугментирования данных к нашему датасету дополнит его почти такими же лицами, но с небольшими отличиями в цвете глаз или оттенке кожи.
Рандомизаторы данных лишь сдвигают элементы в пуле данных, а не создают новые. То есть с их помощью мы можем обменивать черты лиц, например, волосы человека 1 будут скомбинированы со ртом человека 2 и глазами человека 3.
Синтетические данные предоставляют нам совершенно новые лица людей, имеющие характеристики исходного датасета, но не отображающие полностью оригинальное реальное лицо. По сути, создавая синтетические данные, мы воссоздаём нечто, существующее в реальном мире, обладающее его характеристиками, однако не отображающее его непосредственно.
Сами по себе синтетические данные необязательно генерируются компьютером. До эпохи компьютеризации в истории человечества синтетические данные тоже существовали, однако генерировались людьми. Например, ту же генерацию лиц может выполнить человек, рисующий новые лица.
Также могла выполняться генерация числовых данных, только вместо использования вычислительных ресурсов люди применяли познания в математике или статистике. Однако даже с учётом прогресса в математике и теории вероятностей генерация синтетических данных без компьютерных ресурсов — очень длительный и сложный процесс.
Типы синтетических данных по их композиции
Существует два типа синтетических данных: частичные и полные. Частичный тип — это датасет, включающий в себя синтетические данные и реальные данные из наблюдений и измерений. Его примером является сгенерированное изображение автомобиля, вставленное в реальную фотографию пейзажа.

Полный тип — это датасеты, состоящие исключительно из синтетических данных. Их примером может быть сгенерированное изображение автомобиля в симулируемом окружении. При выборе того, будет ли датасет полностью или частично синтетическим, решение следует принимать, исходя из основной задачи. Например, полностью синтетические данные дают больше контроля над датасетом.

В то же время, модели, обученные исключительно на синтетических данных, могут в некоторых случаях не гарантировать наилучшего качества и надёжности. Например, ПО для беспилотных автомобилей лучше обучать и на синтетических, и на реальных данных. Другие модели машинного обучения, применение которых связано с меньшей потенциальной угрозой, можно обучать на одних синтетических данных.
Когда и зачем используются синтетические данные?
Синтетические данные могут использоваться для различных целей, от исследований распознавания радиосигналов до обучения моделей для навигации роботов. На самом деле, синтезированные данные могут использоваться практически для любого проекта, в котором требуется, чтобы компьютерная симуляция прогнозировала или анализировала реальные события. Существует множество важных причин, по которым бизнес может задуматься об использовании синтетических данных.
- Эффективность финансовых и временных затрат. Если у вас нет подходящего датасета, генерация синтетических данных может быть намного дешевле, чем сбор данных событий реального мира. То же самое относится и к временному фактору: синтезирование может занять считанные дни, а для сбора и обработки реальных данных иногда требуются недели, месяцы или даже годы.
- Исследование редких данных. В некоторых случаях данные редки или их сбор связан с опасностью. Примером редких данных может быть набор необычных случаев мошенничества. Пример опасных реальных данных — это дорожно-транспортные происшествия, на которые должны научиться реагировать беспилотные автомобили. В таком случае их можно заменить синтетическими ДТП.
- Устранение проблем с конфиденциальностью. При необходимости обработки или передачи сторонним лицам уязвимых данных следует учитывать вопросы конфиденциальности. В отличие от анонимизации, генерация синтетических данных устраняет любые следы идентификации реальных данных, создавая новые валидные датасеты без ущерба конфиденциальности.
- Простота разметки и контроля. С технической точки зрения, полностью синтетические данные упрощают разметку. Например, если сгенерировано изображение парка, можно легко автоматически присвоить метки деревьям, людям и животным. Вам не придётся нанимать людей для ручной разметки этих объектов. К тому же полностью синтезированные данные легко контролировать и изменять.
Два способа генерации синтетических данных
По сути, существует два основных способа получения синтетических данных.
- Использование генеративных моделей.
- Традиционные способы: специальные инструменты и ПО, а также покупка данных у сторонних сервисов.
Оба варианта можно применять для генерации различных типов синтетических данных. Но прежде чем вдаваться в подробности, мы вкратце объясним, какие генеративные модели используются наиболее часто и какие традиционные методы можно применять.
Генеративные модели
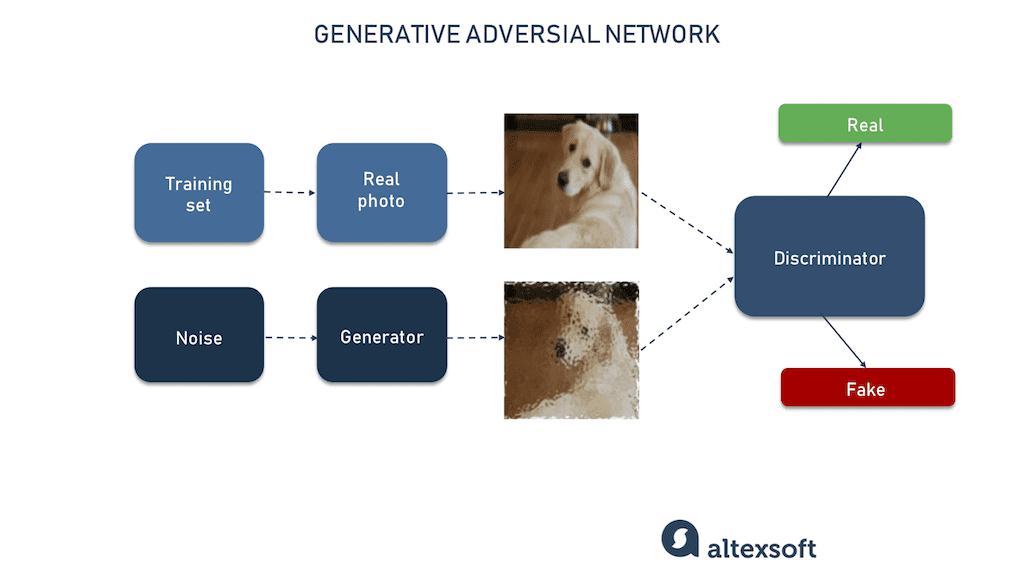
Генеративно-состязательные сети (generative adversarial network), или GAN — это класс самых популярных моделей для синтезирования данных. Они состоят из двух подмоделей: генератора и дискриминатора. Задача генератора заключается в синтезе фальшивых данных, а цель дискриминатора — определить, выглядят ли они фальшивыми или реальными. Две модели работают друг против друга, отсюда и состязательность в названии.
Дискриминатор обучен на реальных данных отличать сгенерированные фальшивые данные от реальных данных. Генератор идентифицирует наиболее реалистичные примеры данных, которые дискриминатор в конечном итоге классифицирует как реальные. Процесс продолжается, пока генератор сможет синтезировать элементы данных, которые дискриминатор окажется не способен отличить от реальных данных.
Допустим, наша задача заключается в генерации при помощи GAN реалистичных фотографий собак. Мы заполняем обучающий датасет реальными фотографиями, обучающими дискриминатор понимать, как выглядят реальные собаки. Затем мы подаём на генератор случайный шум, из которого он шаг за шагом пытается сгенерировать фотографии собак. Генератор отправляет эти фотографии дискриминатору, который, по сути, проверяет, выглядят ли созданные собаки реальными. В процессе работы генератор справляется всё лучше, пока дискриминатор не пометит синтезированное изображение как реальное. GAN могут использоваться для синтеза множества разных типов данных, в том числе изображений, видео, аудио, рукописного текста, табличных данных и многого другого.
Вариационные автоэнкодеры (variational autoencoder) (VAE) специализируются на определении зависимостей в датасете. Они воссоздают примеры данных из датасета, но в то же время генерируют новые вариации. Вариационные автоэнкодеры используются для генерации различных типов сложных данных, например, рукописного текста, лиц, изображений и табличных данных.
Авторегрессивные модели (autoregressive model) (AR) — это класс моделей, занимающийся временными последовательностями и датасетами, связанными с измерениями времени. Модели AR создают данные, прогнозируя на основании предыдущих значений будущие значения. Они широко применяются для предсказания событий будущего, особенно в сферах экономики и экологии. Также они используются для генерации синтетических данных временных последовательностей.
Традиционные методы
Традиционные методы включают в себя получение синтетических данных их генерацией при помощи инструмента или ПО, или получением подобных услуг от сторонних сервисов. Инструменты и ПО (в том числе и бесплатные) могут удовлетворять потребностям тестирования, но их может оказаться недостаточно для высокого качества контента. Также для применения этого метода необходимо наличие в компании ИТ-ресурсов.
С другой стороны, заключение договора с компаниями, предоставляющими синтетические данные, позволяет избавиться от необходимости в собственном ИТ-персонале. Кроме того, обычно сторонние сервисы специализируются в одном конкретном типе генерации синтетических данных, поэтому обладают бОльшим опытом в своей нише.
Типы синтетических данных
Как говорилось ранее, генеративные модели машинного обучения и традиционные способы генерации применимы к любому типу синтетических данных. Ниже мы перечислим пять основных типов и расскажем, какую модель, инструмент и ПО следует использовать для генерации.
Генерация табличных данных
Обычно в табличных данных содержатся более уязвимые и конфиденциальные подробности, чем в остальных. Именно по этой причине их нужно не анонимизировать, а синтезировать. Для анонимизации данных требуется удаление из датасета характеристик, позволяющих идентифицировать человека. Однако этот процесс непрост.
Для анонимизации данных может потребоваться удаление из датасета некоторых элементов идентификации наподобие имени, адреса и пола. Чем больше данных мы удаляем, тем менее ценная информация остаётся для будущего анализа. И даже удаление большого количества конфиденциальных данных оставляет возможность идентификации даже по небольшому объёму информации. За такими случаями внимательно следит закон о защите конфиденциальности GDPR, распространяющийся на всех граждан ЕС и компаний, занимающихся бизнесом в ЕС.
Для генерации табличных данных нужно использовать специализированные модели GAN наподобие CTGAN, WGAN и WGAN-GP, нацеленные на синтез таблиц. Платформа Synthetic Data Vault предоставляет библиотеки для лёгкого обучения синтезированию табличных данных. Также есть и поставщики синтетических табличных данных: MOSTLY AI, GenRocket, YData, Hazy и MDClone. Последний специализируется на синтетических медицинских данных.
Существует множество областей применения синтеза табличных данных: в сфере финансов он используется для экономических прогнозов и выявления мошенничества, в здравоохранении и страховании — для исследования клиентов и событий, в социальных сетях — для изучения поведения пользователей, в потоковых сервисах для анализа поведения и рекомендаций, в маркетинговых и рекламных кампаниях для отслеживания поведения и реакций покупателей.
Инструменты: Synthetic Data Vault
Генерация временных последовательностей
Синтетические данных временных последовательностей в некотором смысле могут считаться табличными данными, однако основное различие между ними заключается в том, что временные последовательности специализируются на данных, привязанных к временному фактору. Для их генерации при помощи моделей можно использовать авторегрессивные модели (AR), поскольку они специализируются на данных временных последовательностей. Также существуют ориентированные на временные последовательности GAN, например, TimeGAN.
Чаще всего синтетические данные временных последовательностей применяются в сфере финансовых прогнозов, прогнозирования спроса, трейдинга, прогнозов состояния рынка, записи транзакций, прогнозов погоды, мониторинга компонентов в механизмах и робототехнике.
Если вкратце, данные временных последовательностей ценны для алгоритмов возможностью изучать паттерны, прогнозировать будущее и выявлять аномалии. Большинство поставщиков синтетических данных временных последовательностей поставляют и табличные данные, поскольку эти два типа данных работают в симбиозе.
Генерация изображений и видеоданных
Существует бесконечное множество способов применения синтетических данных изображений и видео. Однако мы можем определить две основные ветви, в которых требуется синтез визуальных данных. Это компьютерное зрение (computer vision) и генерация лиц.
В процессе компьютерного зрения машина обучается тому, что она видит, с целью выполнения конкретного действия. Это очень важно для робототехники и автомобилестроения. В обеих сферах компьютер должен различать объекты и фон, расстояния между ними и их размеры.
NVIDIA Omniverse — это инструмент 3D-симуляции для различных типов проектов. Компания выпустила Isaac Sim — приложение роботизированной симуляции, упрощающее тестирование машин в реальных окружениях. Также существует созданная MIT платформа ThreeDWorld, позволяющая создавать 3D-миры на основании физики реального мира. OneView предоставляет инструменты для синтезирования геопространственных данных. CVEDIA и Parallel Domain создают данные для обучения компьютерного зрения.
Генерация лиц — это, по сути, синтезирование лиц несуществующих людей. This Person Does Not Exist — это сервис, предлагающий бесплатно фальшивые реалистичные фотографии людей. Генерацию человеческих лиц можно использовать для подготовки моделей машинного обучения с целью распознавания лиц, например, в сфере безопасности и робототехники. Datagen — это поставщик услуг, специализирующийся на синтезе данных лиц, людей и объектов.
Общие методы синтезирования изображений включают упомянутые выше модели GAN, а также инструменты наподобие Unity, Unreal Engine и Blender. Эти программные решения не только упрощают генерацию, но и предоставляют трёхмерные датасеты для многократного применения.
Генерация текстовых данных
Синтезированые текстовые и звуковые данные реже используются в бизнесе, и в основном применяются в исследованиях и арт-проектах. Тем не менее, текстовые данные можно использовать для обучения чат-ботов, алгоритмов, проверяющих письма на спам, или моделей машинного обучения, выявляющих нарушения правил.
Говоря о синтезированном тексте, стоит упомянуть модель генерации текстов GPT-3 (Generative Pre-trained Transformer 3). GPT-3 — это авторегрессивная модель, генерирующая письменные тексты, напоминающие человеческие; их можно использовать для подготовки моделей машинного обучения к распознаванию или пониманию текстов. Также существует онлайн-инструмент Text Generation API, который при помощи модели GPT-2 создаёт короткие абзацы текста на основании введённых данных.
Однако в области синтезированных текстовых данных существует не так много сервисов. Мы предполагаем, что причина этого в том, что в вебе уже очень много текстовых данных для обучения алгоритмов, поэтому потребность в синтезировании отсутствует.
Модели: GPT-3.
Инструменты: Text Generation API.
Сервисы: Gretel.
Генерация аудиоданных
Синтезирование аудиоданных, как и текстовых данных, тоже не очень распространённая услуга. Возможно, причина этого заключается в том, что для создания различных частот и манипулирования ими не требуется синтез, это можно делать в специальном ПО. Существуют профессиональные пакеты наподобие Ableton Live и iZotope; более ориентированные на кодинг наподобие Max и Pure Data; а также очень простой Audacity.
Синтетические аудиоданные имеют потенциал в области применения text-to-speech и голосового управления роботами. Получить данные для машинного обучения можно множеством различных способов; один из самых популярных — это Text-to-Speech компании Google. Он позволяет выбирать пол, языки и акценты/варианты английского.
Ещё одной широкой сферой применения синтетических данных являются исследования, в частности, в физике. Как говорилось выше, это может быть обучение моделей для радиолокационного слежения на синтетическом датасете аудиоданных. В таком случае проще получить пул искусственных звуков, чем записывать их в реальном мире. Для получения датасетов аудиоданных можно воспользоваться источником DagsHub, содержащим размеченные датасеты звуков.
Сервисы: Text-to-Speech, Replica.
Способы применения синтетических данных
Давайте рассмотрим интересные способы применения синтетических данных в бизнесе, поскольку они постепенно становятся популярным подходом к получению обучающих данных для задач машинного обучения.
Борьба с мошенничеством
American Express обучила ИИ-модели борьбы с мошенничеством на синтетических данных. Компания использовала GAN для синтеза случаев мошенничества, по которым у неё было недостаточно данных. Задача заключалась в аугментировании реального датасета синтезированными данными, чтобы сбалансировать доступность различных видов мошенничества.

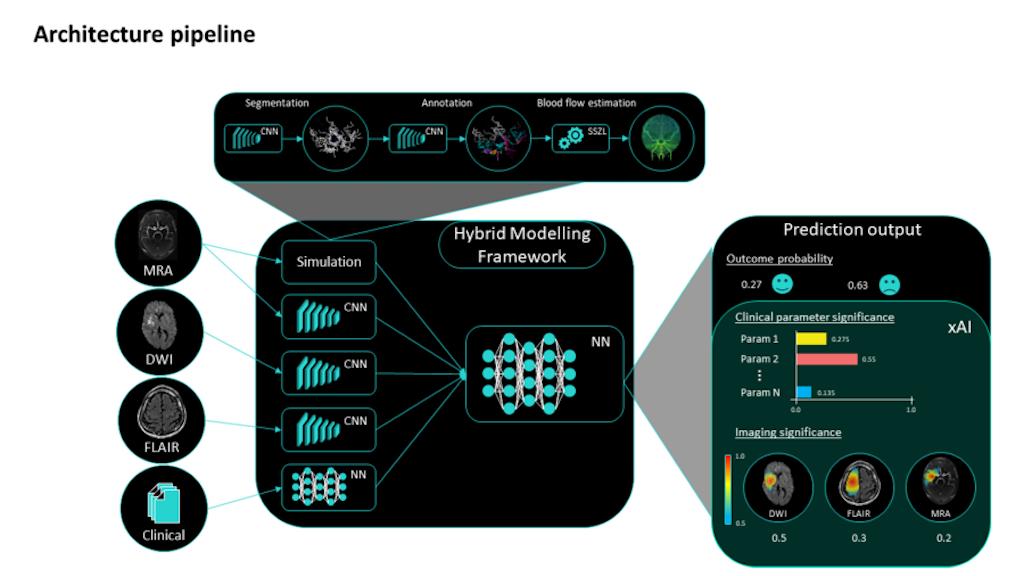
Медицинские симуляции
Исследователи проекта PREDICTioN2020, проведённого Charité Lab для применения искусственного интеллекта в медицине, хотели создать всеобъемлющую платформу для прогнозирования результатов инсультов. Они использовали гибридную модель, в котором сочетались данные изображений и клинические параметры. Для создания биофизиологических симуляций использовались синтезированные данные.
Анализ лиц
Компания Microsoft провела исследование Fake it till you make it: face analysis in the wild using synthetic data alone. Исследователи сгенерировали разнообразный датасет трёхмерных человеческих лиц с разметкой, который использовали как материал для подготовки моделей машинного обучения в компьютерном зрении, локализации черт и парсинга лиц. Результаты проекта показали, что синтетические данные способны с высокой точностью соответствовать реальным данным.

Разработка чат-ботов
Стартап Moveworks разработал чат-бота, обученного на синтетических данных, чтобы отвечать на вопросы клиентов о финансах, кадровых ресурсах и особенно об ИТ. Синтетические данные использовались для обучения на случаях, которых в реальных данных было недостаточно. Бот Moveworks помогает пользователям решать простые задачи наподобие сброса пароля, подключения устройства или установки ПО.
Симуляция моделирования оттока
Швейцарская страховая компания La Mobilière использовала синтетические данные для обучения модели оттока. Прогнозирование оттока (churn prediction) — это одна из распространённых задач машинного обучения, заключающаяся в выявлении и прогнозировании клиентов, которые с большой вероятностью хотят прекратить пользоваться услугами. Эффективное прогнозирование оттока даёт бизнесу время и информацию для проактивной связи с клиентами, чтобы предложить им лучшие условия и убедить остаться. При помощи синтетических данных компания решает проблему с конфиденциальностью. Начиная с 2017 года в Швейцарии начали внедрять новые требования по использованию конфиденциальных данных, поэтому обучать модели на реальных данных было бы сложно и дорого. Благодаря синтетическим табличным данным La Mobilière смогла получить данные для обучения модели, соответствующей требованиям законодательства.
Виртуальный завод
NVIDIA спроектировала пространство виртуального завода для навигации роботов и симуляции производства компании BMW. Цель симуляции заключалась в прототипировании будущих производственных помещений и создании его цифрового двойника. В этой смешанной реальности отделы BMW по всему миру могли совместно тестировать, конфигурировать и оптимизировать виртуальное производство при помощи различных программных пакетов. Синтетические данные использовались для обучения моделей движений роботов в виртуальной среде завода BMW.

Обработка диалогов
Amazon обучила на синтетических данных Alexa для распознавания запросов на нескольких языках. При добавлении в систему нового языка пул данных запросов для модели машинного обучения крайне мал. В таком случае Amazon применяет синтетические данные в сочетании с реальными для обогащения своей выборки и обучения моделей понимания естественного языка (natural language understanding, NLU) Alexa.

Беспилотные автомобили
Waymo использует синтетические данные для обучения беспилотного транспорта. Waymo создала собственную глубокую рекуррентную нейронную сеть (RNN) под названием ChaufferNet. В этом окружении автомобиль обучается на размеченных синтетических и реальных данных безопасно двигаться, распознавая объекты и соблюдая правила дорожного движения. RNN имитирует и плохие, и хорошие ситуации на дороге, чтобы беспилотные автомобили могли им учиться.

Ограничения синтетических данных
Хотя использование синтетических данных даёт множество преимуществ, всё равно остаются случаи, когда их лучше не применять. Процесс синтезирования данных быстрее и проще, чем сбор реальных данных, однако он всё ещё сложен и требует труда опытных специалистов. Неправильно синтезированные данные могут не описывать события реального мира правильно или содержать перекосы.
Кроме того, в некоторых случаях сбор реальных данных может быть более выгодным или полезным. Например, социологические исследования, собирающие вариации мнений об актуальных событиях, гораздо более надёжны и достоверны, чем данные, сгенерированные машиной.
Сравнение результатов использования синтетических и реальных данных
Реальные данные чрезвычайно ценны, однако возможности их обработки ограничены, например, из-за проблем с конфиденциальностью; иногда они становятся слишком дорогими, что отражается на времени и затратах на их получение. И тут на помощь приходят синтетические данные, которые генерируются быстрее, дешевле и в полностью контролируемом окружении.
Посмотрите это видео об использовании синтетических данных компанией OpenAI на модели в движке Unity. Задача синтеза заключалась в обучении манипулятора робота поворачивать куб с буквами на каждой из сторон в нужное положение; восприятие машины записывалось через камеру, фиксирующую все движения манипулятора.
Человеческий глаз способен воспринимать визуальную информацию с частотой 30 кадров в секунду, то есть один год наблюдений с такой частотой аналогичен миллиарду кадров. Однако компьютер не обязан соответствовать этому медленному паттерну. В приведённом выше примере манипулятор робота обучался на 300 миллиардах симулированных кадров, что, по сути, равно 300 годам человеческой жизни.
