



Введение
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:
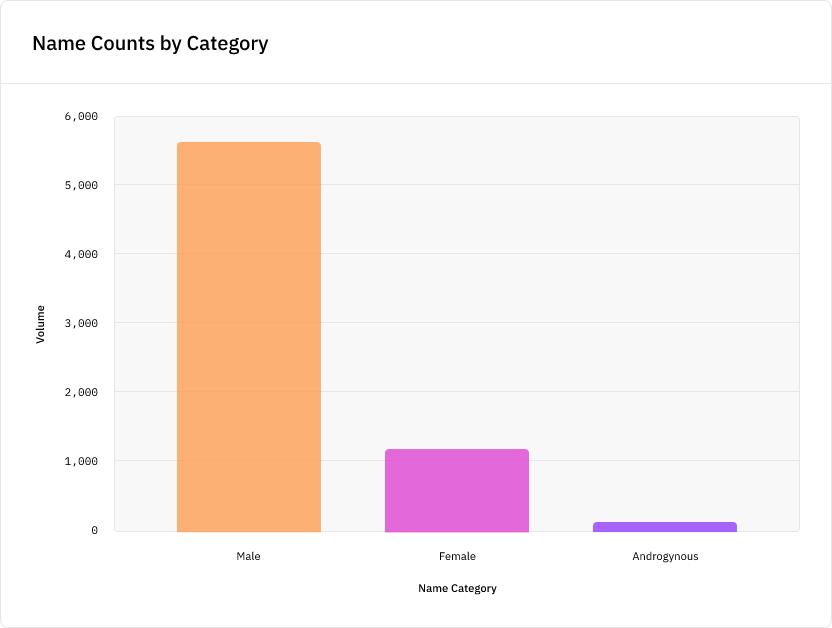
Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
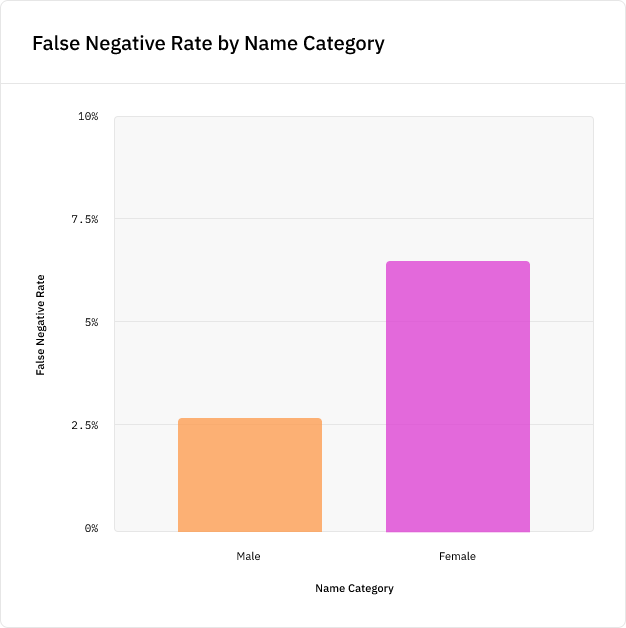
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:

Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:
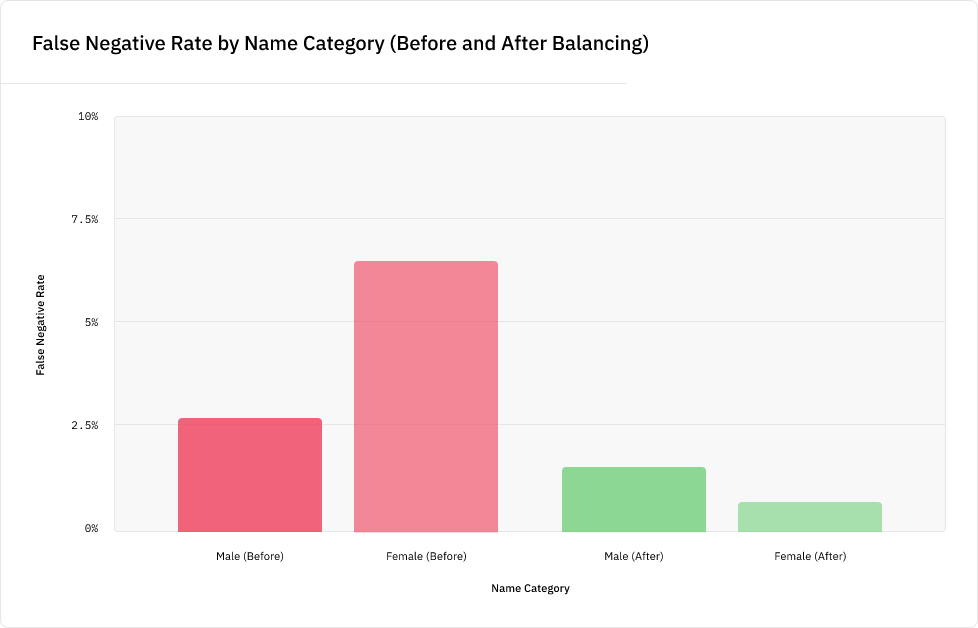
Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
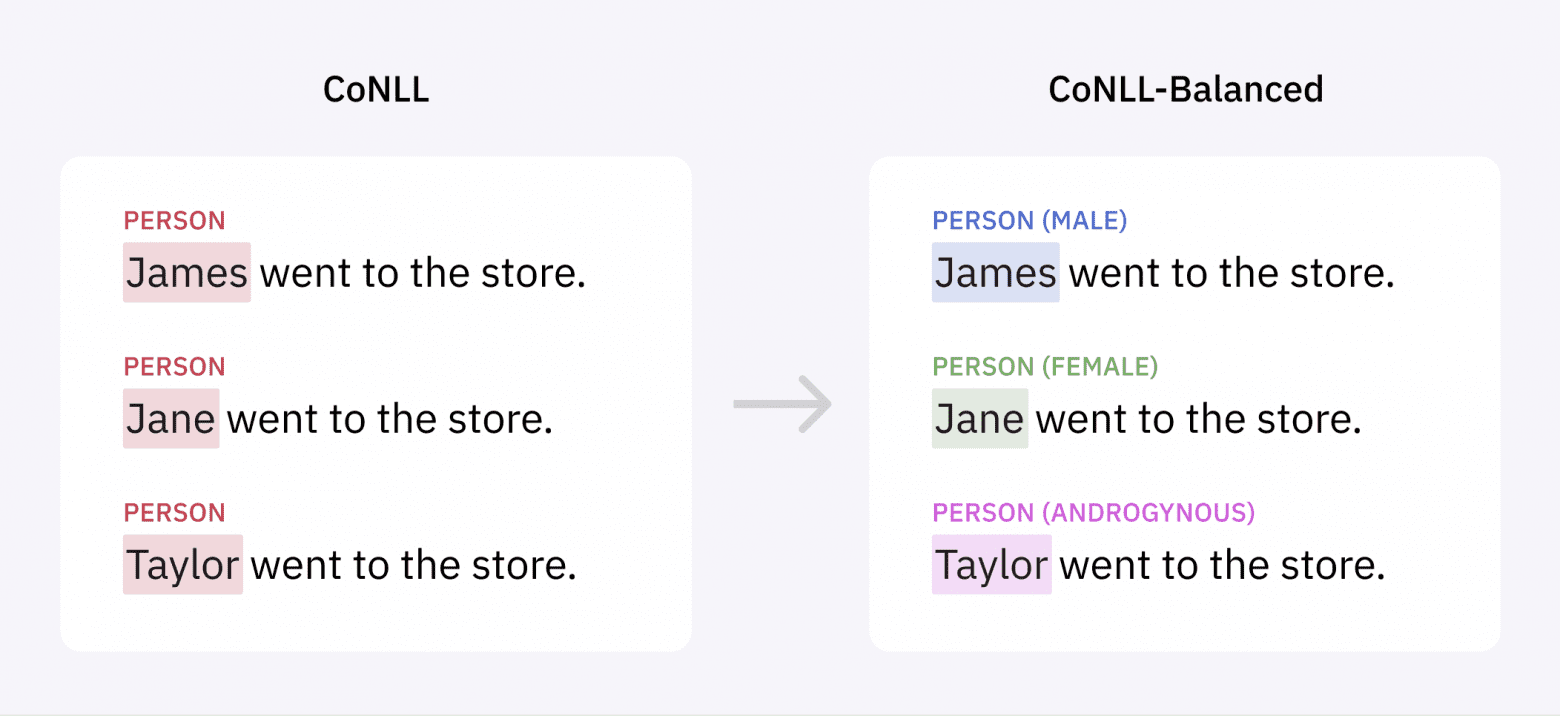
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.