



Введение
Методология agile-разработки ПО, популяризированная примерно в 2010 году манифестом Agile Software Development, продвигает идею адаптивного планирования, эволюционного развития, быстрой доставки и непрерывного совершенствования как ключевых свойств, обеспечивающих быстрый и гибкий отклик на постоянно ускоряющиеся изменения рынка и его требований.
Поскольку линейные каскадные модели, позаимствованные из отраслей производства и строительства, оказались неспособны обеспечить конкурентное преимущество в постоянно усложняющемся и быстро меняющемся мире ПО, модели Agile и Scrum стали де-факто стандартом для современной разработки ПО.
Но что произойдёт, когда мы осуществим переход к Software 2.0? В своём посте от 2017 года Андрей Карпати предвидел фундаментальные изменения в мире разработки ПО:
Машинное обучение сейчас постепенно завоёвывает и преобразует каждую отрасль при помощи «сквозных» прогнозирующих модулей, уже интегрированных в производственные процессы практически всех продуктов и услуг (пару примеров можно увидеть здесь).
Однако современные модели машинного обучения неэффективно обучаются с нуля и статически разворачиваются на каждом цикле итерации, и из-за этого чем-то походят на обычную последовательную модель каскада (жёсткого и плохо адаптируемого).
Что если мы сможем привнести то, чему мы научились за последние пятьдесят лет Software 1.0, в Software 2.0?
Непрерывное обучение как Agile машинного обучения
Оказывается, это можно сделать! За последние несколько лет мы стали свидетелями серьёзного прогресса в области машинного обучения, называющейся "непрерывным обучением" (Continual Learning), основная идея которой заключается в постоянном инкрементном обучении моделей в процессе появления новых данных (требований). Это даёт огромные преимущества, схожие с преимуществами методологии Agile:
- Эффективность: так как процесс непрерывен, нам не нужно начинать с нуля каждый раз, тратя огромные вычислительные ресурсы на повторное обучение модели тому, что она уже и так знает.
- Адаптивность: так как процесс обучения очень быстр, эффективен и гибок, мы гарантируем беспрецедентный уровень адаптации и специализации.
- Масштабируемость: лишняя трата вычислительных ресурсов и памяти остаётся ограниченной (и низкой) на протяжении всего жизненного цикла продукта/сервиса, позволяя нам масштабировать интеллект, обрабатывая новые данные.
Хотя часто считается, что непрерывное обучение является удобным свойством, которое нужно исследовать для создания агентов Artificial General Intelligence (AGI), а его практическое использование будет ограничено применением во встроенных вычислительных платформах (без облака), в данном посте я хочу заявить, что в течение ближайших лет оно повсеместно станет обязательным свойством каждой системы машинного обучения, активно используемым в средах продакшена.
Важность непрерывного обучения
На конференциях можно услышать подобные утверждения: «Системы машинного обучения невероятно неэффективны по сравнению с мозгом!», «Методики машинного обучения невероятно требовательны к объёмам данных!», «Алгоритмы машинного обучения предназначены только для суперкомпьютеров!». Разумеется, так и есть. Например, в контексте зрения установлено, что для развития достаточно хорошей системы зрения ребёнку нужно три-пять лет, после чего он совершенствует и адаптирует к окружающей среде в течение всей своей жизни. Почему для систем машинного обучения ситуация должна отличаться?
Мы ожидаем, что система машинного обучения должна обучаться за считанные минуты и выучить идеальную модель внешнего мира. Но вместо этого нам стоит нацелиться на создание системы непрерывного обучения, способной надстраивать свои предсказательные возможности на основе изученного ранее, компенсируя предыдущие искажения и дефицит данных, а также эффективно адаптироваться к новым условиям окружающей среды в процессе появления новых данных.
По моему мнению, почти так же, как в Software 1.0, где мы спустя более пятидесяти лет опыта «разработки ПО» признали невозможность создания сложной системы при помощи исключительно линейной модели разработки, то же самое мы осознаем и в случае Software 2.0.
Оказывается, некоторые люди из нашей отрасли уже начинают признавать эти изменения. Например, в Google Play и других сервисах Google с Tensorflow Extended:
Возможно, в некоторой степени, в Tesla:
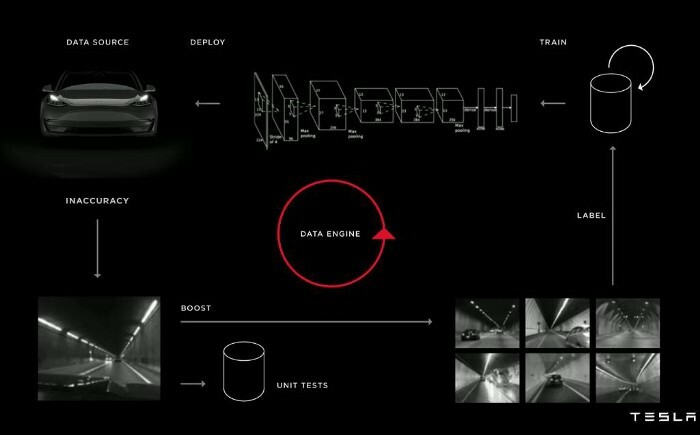
И во многих других компаниях, предоставляющих MLaaS, например, Amazon SageMaker, IBM Watson и так далее, или в стартапах наподобие Neurala и Cogitai.
Почему многие компании начинают инвестировать в непрерывное обучение? Потому что оно обходится гораздо дешевле! Давайте рассмотрим пример из практики.
Простой пример: снижение счетов на AWS на 45% или более
Итак, давайте ради простоты представим, что у вас есть веб-компания и вам нужно распознавать содержимое изображений, публикуемых на вашей веб-платформе её пользователями.
К сожалению, у вас нет данных заранее, но имеются небольшие наборы новых изображений с метками (например, тэги пользователей), получаемые в конце каждого дня (цикла итерации), а вы хотите максимально быстро адаптировать свои предсказательные модели для повышения удобства пользователей и показа рекомендаций лучшего контента платформы.
По современным стандартам это обозначало бы, что вам нужно повторно обучать всю модель машинного обучения с нуля на всех накопленных данных и повторно разворачивать её вместо старой модели. Однако это чрезвычайно расточительно с точки зрения вычислительных ресурсов и памяти, поскольку вы постоянно обучаете модель одному и тому же.
Что если мы просто будем дополнять её новыми изображениями? В своей недавней статье "Fine-grained Continual Learning" (воспринимайте указанные ниже значения с долей скептицизма, поскольку они не приведены в статье, а спроецированы для этого поста) мы показали, что достаточно простая стратегия непрерывного обучения AR1*, проверенная в ситуации обучения на 391 обучающем наборе, может:
- уменьшить требуемые вычислительные ресурсы в среднем примерно на 45% на протяжении её жизненного цикла: изначально её преимущество составляет 0% по сравнению со стратегией повторного обучения и развёртывания, а в конце для 391-го обучающего набора требуется примерно на 92% меньше вычислительных ресурсов. При этом нужно учитывать, что стратегии повторного обучения и развёртывания требуется всё большее количество эпох (от 4 до 50) для каждого набора, а в AR1* постоянно используется 4 эпохи.
- уменьшить лишние затраты памяти в среднем примерно на 49% на протяжении её жизненного цикла: так как нам нужно хранить в памяти не все накопленные на текущий момент данные обучения, а только те, которые находятся в текущем обучающем наборе, снижение лишних затрат памяти составляет от 0% при первом обучающем наборе до примерно 99% при 391-м обучении по сравнению с стратегией повторного обучения и развёртывания.
При этом в конце жизненного цикла нашей системы распознавания объектов теряется лишь примерно 20 процентных пунктов точности.
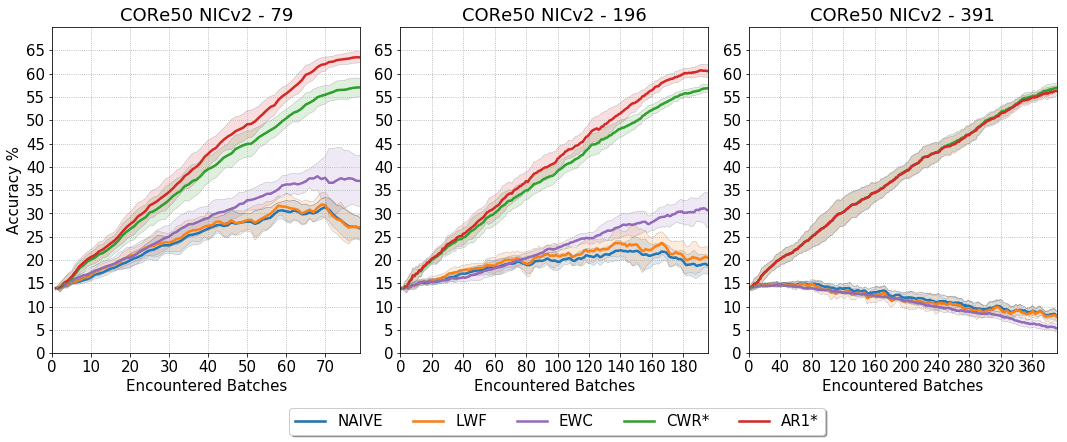
Так как стратегии непрерывного обучения всё лучше и лучше преодолевают различия в точности с неэффективной стратегией повторного обучения и развёртывания ("Cumulative"), на протяжении жизненного цикла мы можем сэкономить более 45% вычислительных ресурсов и примерно 49% памяти.
Более того, стоит заметить, что в этом простом примере мы рассмотрели только ограниченное количество инкрементных обучающих наборов (391), а стратегия непрерывного обучения полностью демонстрирует свои преимущества, когда количество обучающих наборов потенциально выше. Это значит, что показатели на протяжении жизненного цикла могут продолжать расти: чем длиннее жизненный цикл, тем больше повышается эффективность.
Подведём итог: системы непрерывного обучения пока не готовы заменить современные системы машинного обучения (с повторным обучением и развёртыванием). Однако я считаю, что множество смешанных стратегий окажется очень полезным во многих сферах реального применения с хорошим балансом между скоростью/эффективностью адаптации и показателями точности.
Предвидя будущее Software 2.0, я не представляю другого способа эффективного патчинга системы, улучшения её характеристик и адаптации к требованиям всё быстрее меняющегося международного рынка.