



У каждой компании-разработчика БА (беспилотных автомобилей) есть собственный подход к выбору подходящего датчика, расположению датчиков и использованию общего массива собираемых данных. Лидар, прошедший за последние годы долгий путь развития, становится всё более важным устройством, поскольку играет фундаментальную роль в обеспечении безопасного перемещения БА по дорогам. Несмотря на заявления Илона Маска, отрасль БА в целом убеждена в том, что этот датчик и его возможности — ключ к успеху автономности. И в самом деле, в отличие от камер, датчики-лидары способны хорошо проявлять себя в условиях плохой видимости, например, в плохую погоду, или даже лучше разбираться с тенями и сложным освещением, с которыми камеры испытывают трудности.
Когда беспилотный автомобиль попадает на дорогу, через все эти датчики он собирает огромные объёмы данных. Но какова судьба этих данных и для чего они используются? Один из самых важных способов использования данных — обучение моделей машинного обучения, чтобы беспилотные автомобили или любые другие автономные системы могли учиться перемещению в окружающем мире. Что же это значит? И как модель может учиться на этих данных? Для этого применяется процесс под названием «аннотирование и разметка данных», требующий огромного объёма человеческого труда. На самом деле, для аннотирования одного часа вождения может потребоваться до 800 человеко-часов.
На практическом уровне это значит, что каждое изображение каждого кадра должно проверяться мозгом человека, который, нужно признаться, до сих пор намного умнее в понимании окружающего мира, чем любая автономная система. Человек размечает и аннотирует каждый объект в сцене, или, по крайней мере, тщательно проверяет метки, автоматически сгенерированные алгоритмами. Всем объектам в каждом кадре необходимо дать название. Точно так же как ребёнок в садике раскрашивает рисунки в соответствии с категориями, мы учим компьютеры распознавать и категоризировать объекты.
Что такое аннотации изображений
Каждый день мы видим тысячи изображений, поэтому довольно просто понять, как выполняется разметка изображений в наборах данных. Существуют разные способы описания и идентификации объектов таким образом, чтобы они были понятны машинам, и одним из самых распространённых является отрисовка ограничивающих прямоугольников вокруг объектов:

Как видите, каждый объект на изображении размечен в соответствии с двумя основными классами: «Pedestrian» (пешеход) или «Car» (автомобиль). В данном случае различия очень высокоуровневые и не очень подробные, но, как можно догадаться, задача аннотирования может быть гораздо более детализированной, а классы могут быть более подробными или иметь специфические атрибуты. Например, вместо того, чтобы разметить кого-то просто как «пешехода», его можно разметить как мужчину или женщину. А объекты, допустим, автомобиль, можно размечать как объект со включенными или выключенными фарами.
Но наш мир не плоский, и в разметке изображений можно пойти ещё дальше и попробовать передать трёхмерность при помощи кубоидов вместо ограничивающих прямоугольников, например, как на изображении ниже.

Выбранные типы меток (ограничивающие прямоугольники, кубоиды и т. п.) и уровень точности в основном определяются целью использующих их инженеров и способом применения размеченного набора данных.
Как говорилось ранее, камеры — это не единственные датчики, используемые в автономных системах со зрением. Как же выглядят наборы данных лидаров? Если вкратце, то это облако точек. Лидар испускает лазерные лучи вокруг себя и измеряет время, за которое сигнал долетит до объекта и вернётся в приёмник. Благодаря этому лидар может построить 3D-модель мира, отрисовывая точку в пространстве каждый раз, когда один из его лучей лазеров на что-то наткнётся. Или, если точнее, на данный момент это самый лучший способ визуализации собранных лидаром данных. Приблизительно он выглядит как на изображении:

Аннотирование и разметка данных лидара по сути очень похожи на разметку изображений, но отличаются на практике по простой причине: это 3D-модель на плоском экране. Кроме того, людям приходится иметь дело с огромным количеством точек (порядка миллионов), которые не ограничены конкретными поверхностями или границами. Поэтому даже человеческому мозгу сложно понять, какая точка принадлежит какому объекту, и если приблизить изображение с облаком точек, это становится очевидно. Даже в случае данных лидара аннотирование в основном выполняется на основе тех же идей, которые лежат в основе разметки изображений, например, ограничивающих прямоугольников или кубоидов. См. пример:
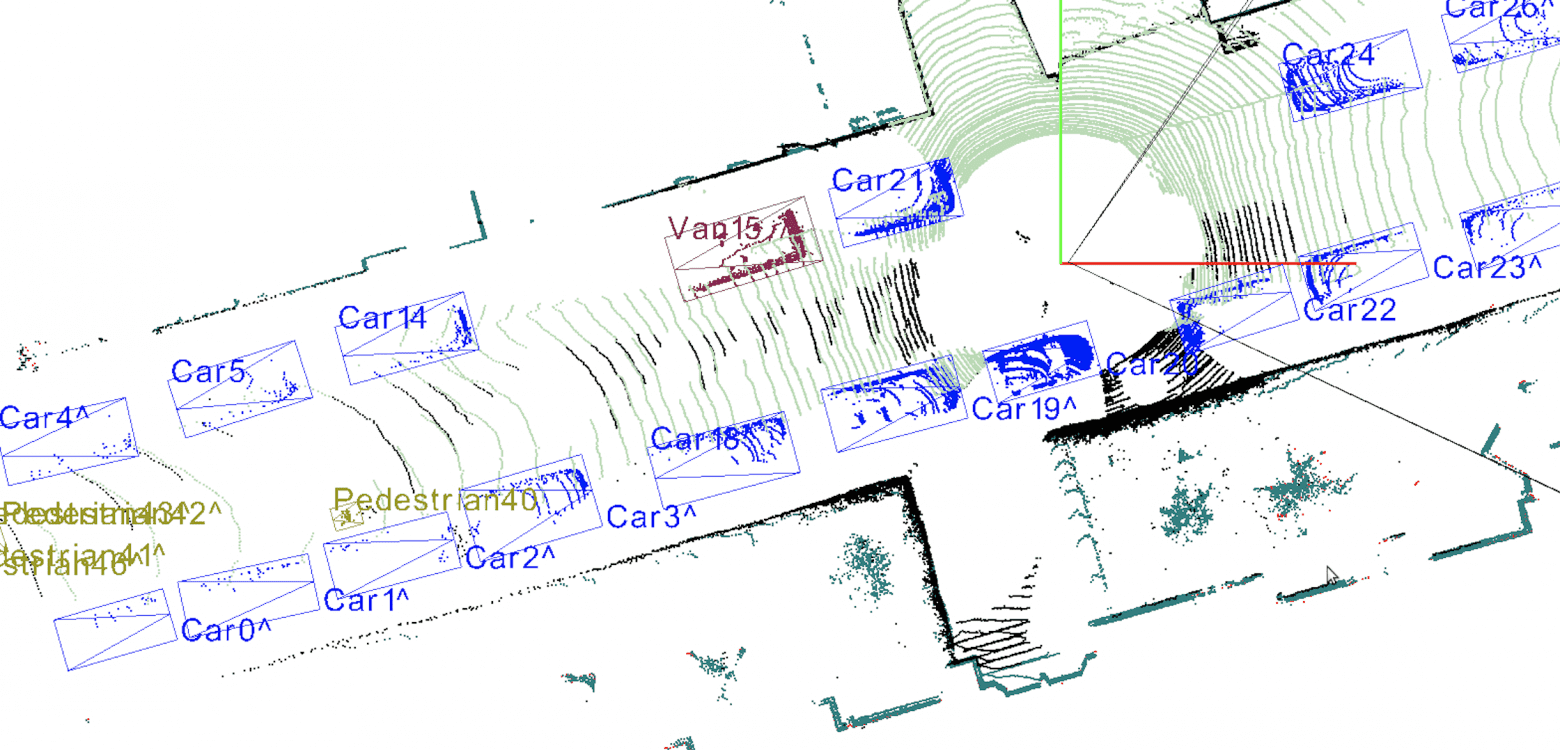
Можно ли придумать что-то получше прямоугольников?
Сейчас вам уже должно быть понятно, что мы очень неплохо умеем распознавать окружающее объекты, и для этого нам не нужны ограничивающие прямоугольники или кубоиды. Обучение машин распознаванию и интерпретированию окружений через разметку изображений прямоугольниками — очень практичный и довольно простой, но не самый подробный и информативный процесс.
Более глубокого уровня описания и понимания можно достичь при помощи так называемой семантической сегментации. Например, при отрисовке прямоугольника вокруг объекта на изображении в него попадает довольно много пикселей, которые на самом деле не принадлежат этому объекту. Семантическая сегментация преодолевает эту проблему при помощи разметки каждого отдельного пикселя на изображении. В результате (см. пример ниже) каждый пиксель оказывается раскрашенным в соответствии с классом, к которому он принадлежит. Пешеходы красные, деревья зелёные, а машины синие. Эти метки присваиваются на уровне пикселей, а не на более общем и неточном уровне прямоугольников. Благодаря этому достигается гораздо более подробная интерпретация мира.

Если нам нужно углубиться ещё сильнее, то мы переходим к сегментации экземпляров. По сути, это означает, что мы не только различаем объекты, принадлежащие к определённым классам, но и хотим научить машину распознавать каждый отдельный объект как конкретный «экземпляр» более общего класса. Здорово иметь возможность распознавания людей, но ещё лучше научиться идентифицировать каждого человека в классе «люди», потому что они не полностью эквивалентны друг другу. Сегментация экземпляров (Instance segmentation) выглядит следующим образом:

Семантическая сегментация и семантическое понимание сцен критически важны для широкого спектра применений в беспилотных автомобилях. Поэтому должен существовать какой-то их аналог для наборов данных лидаров, и он существует, однако его создание связано с серьёзными трудностями.
Данные изображений кодируются в пикселях, а данные лидаров представлены точками, разбросанными по 3D-окружению. То есть для семантической сегментации точек лидара нужно связать каждую точку с конкретным классом объектов, и таким образом нужно раскрасить миллионы точек. Посмотрите на семантически размеченный кадр:

Задача ручного сегментирования каждой отдельной точки очень трудозатратна и требует много внимания, иначе машина не сможет получить чёткое понимание о мире.
Самое сложное в этом контексте — это проблема последовательности кадров. Беспилотные автомобили проезжают по дорогам множество километров, создавая последовательности данных лидаров. То есть необходимо разметить каждую точку в каждом кадре, что само по себе является объёмной работой для человека. Почему важна проблема последовательностей и как она сегодня «частично» решена?
Решение проблемы последовательностей
В области изображений и ограничивающих прямоугольников проблема последовательностей частично решаема. Один из основных современных подходов заключается в том, что живые разметчики аннотируют только отдельные «ключевые» кадры в последовательности, а интеллектуальные алгоритмы ПО при помощи математических процессов на основе интерполяции вычисляют, где разместить метки (прямоугольники) в кадрах (изображениях) между ключевыми кадрами. В такой ситуации важную роль играет выбор ключевых кадров и в зависимости от этого результаты работы ПО могут быть лучше или хуже.
Если же мы перейдём к сфере семантической сегментации последовательностей 3D-данных лидаров, то эта проблема перестаёт быть решаемой, то есть сегодня нам по-прежнему сложно семантически сегментировать длинные последовательности эталонных данных лидаров быстрым, точным и эффективным образом — не только с точки зрения человеческого труда, но и с точки зрения вычислительной эффективности.
И это огромная проблема для всей отрасли беспилотных автомобилей. С одной стороны, семантически размеченные данные лидаров могут обеспечить множество преимуществ и дать доступ к широкому спектру инноваций и достижений в этой сфере. С другой стороны, крупномасштабная семантическая сегментация данных лидаров слишком неудобна, ресурсоёмка и дорога. Считается, что недоступность набора данных лидаров с семантической сегментацией не позволяет компаниям, занимающимся беспилотными автомобилями, достичь важных целей на пути к автономности машин.
Технология аннотирования Deepen 4D LiDAR решает проблему создания семантической сегментации и сегментации экземпляров длинных последовательностей данных лидаров высокоэффективным и точным образом. Теперь мы можем сегментировать эти длинные последовательности за минимальное время и с превосходными результатами по сравнению с тем, что было доступно раньше.
Технология Deepen 4D LiDAR в действии:

Преимущества семантической 4D-сегментации длинных последовательностей данных лидаров
Выгляните в окно. Возможно, вы увидите в нём дорогу, парк или другое здание. Что бы вы ни видели, вам очевидно, что не всё в мире за пределами окна можно описать как прямоугольник. Например, вспомните атмосферные явления или жидкости и газы. Кроме того, во многих случаях прямоугольники накладываются друг на друга: например, сидящий на стуле человек или автомобиль, припаркованный прямо под кроной большого дерева. Во всех этих случаях прямоугольники не могут очень точно указать, где находится какой объект — это достаточно свободная форма аннотирования и разметки.
Именно поэтому так важна семантическая сегментация, и она становится всё более важной для инструментов разметки данных лидаров, которые являются фундаментальной частью системы восприятия мира беспилотных автомобилей. Разметка данных лидаров с помощью прямоугольников определённо создаёт не самую точную картину мира, в котором должны безопасно перемещаться беспилотные автомобили. С другой стороны, данные с семантической сегментацией обеспечивают создание моделей машинного обучения с более глубоким и точным интерпретированием окружений, на которые могут полагаться БА.
Кроме того, как нам гарантировать достаточно высокую безопасность разрабатываемых нами автономных систем (то есть беспилотных автомобилей) для перемещения по дорогам без вмешательства человека? Критически важными в этом являются бенчмарки. Бенчмарки — это процесс сравнения результатов работы ПО в понимании ситуации в реальном окружающем мире (эталонных данных). Сегодня создаются карты высокого разрешения, имеющих точность до миллиметров: на созданной карте нужно с огромной точностью указать каждое дерево, дорожный знак и тротуар. Так как описывающие реальный мир HD-карты невероятно точны, такими должны быть и наши алгоритмы. Обучение моделей машинного обучения на семантически сегментированных эталонных данных на уровне точек считается лучшим способом обеспечить такой уровень точности.
Это лишь одна из сфер конкретного применения, в которых семантическая 4D-сегментация может стимулировать прогресс. Однако нет сомнений в том, что возможность лёгкого сегментирования последовательностей облаков 3D-точек в больших масштабах значительно повлияет на многие автономные системы, например, на сельскохозяйственных роботов, воздушных дронов и даже 3D-приложения AR и VR в реальном мире.
А пока наслаждайтесь поездками за рулём и не забывайте пристёгиваться… Но возможно, очень скоро управлять автомобилем вам не потребуется.
Мы в компании пробовали Supervise. ly и SUSTechPOINTS, но может есть еще что-то более удобное?