


Чтобы двигаться быстро, мы уже на ранних этапах пытаемся добиться согласованности с требованиями клиентов. Мы стремимся понять, чего хотят наши клиенты, и для чего им это нужно, чтобы мы могли использовать свою экспертизу в продуктах и опыт работы для разметки их данных с высоким качеством и учётом их задач в области машинного обучения. При проектировании и создании конвейеров аннотирования данных мы активно сотрудничаем и тщательно продумываем все аспекты. Это одна из множества причин, по которым клиенты продолжают выбирать Scale в качестве партнёра для разработки ИИ.
Мы проектируем конвейеры аннотирования данных, соответствующие задачам клиентов в сфере машинного обучения
Мы начинаем с понимания того, чего стремится добиться клиент. Что конкретно должна будет делать модель ИИ? Будет ли она применяться в беспилотном автомобиле, например, для прогнозирования действий другого агента? Или будет использоваться в приложении, способном распознавать и отслеживать объекты для складского учёта? Исходя из этого, мы начинаем разбираться:
- На каких данных будет «обучаться» модель?
- Какие данные будут использоваться для получения инференса модели после её внедрения на производстве?
- Как должен выглядеть идеальный результат?
- Как определяется хороший (или плохой) результат инференса модели?
Мы выяснили, что успех проекта ИИ сильно коррелирует с качеством и спецификой использованных данных обучения. Это означает, что применение широкого или обобщённого массива данных обучения обычно не является самым эффективным или быстрым способом построения модели машинного обучения. Поэтому мы совместно с клиентами проектируем нацеленные на конкретную задачу конвейеры аннотирования, непосредственно соответствующие их планам по машинному обучению. Такой подход помогает им достигать своих KPI и контрольных точек проектов.
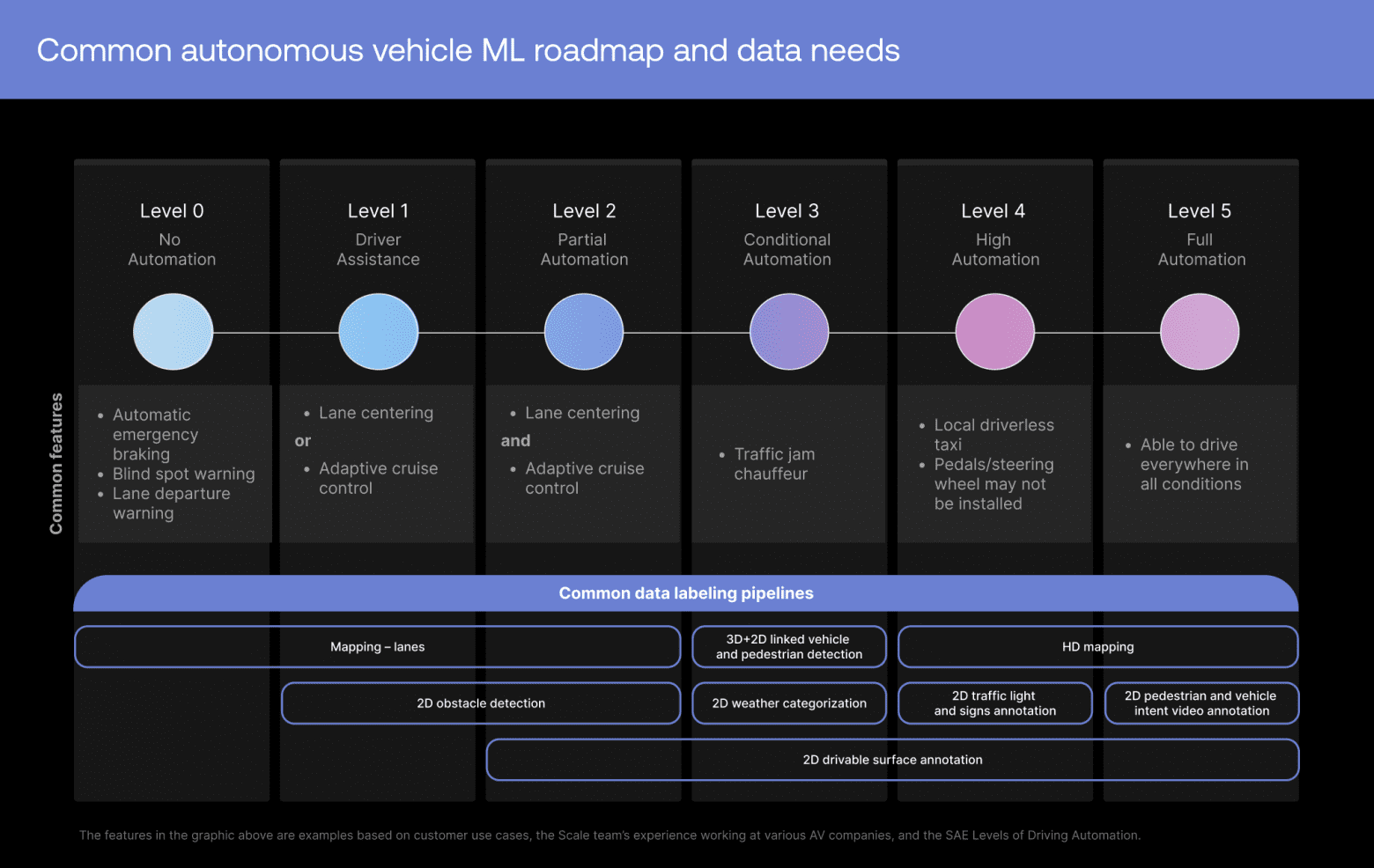
Например, новые клиенты часто просят нас воссоздать публичный массив данных широкого назначения, например, предназначенный для беспилотных автомобилей NuScenes, который мы выпустили совместно с Aptiv. Однако после глубокого изучения их планов по машинному обучению мы выявляем их вторичные цели (например, планирование нахождения в полосе движения и распознавание намерений пешеходов), а также желаемые сроки для каждой. Затем мы создаём специализированные конвейеры, генерирующие необходимые данные обучения с более высоким качеством и скоростью, чем если бы клиент занимался этим самостоятельно. На самом деле, наша скорость работы часто помогала клиентам уложиться в важные дедлайны, например, успеть к публичной конференции или демонстрации.
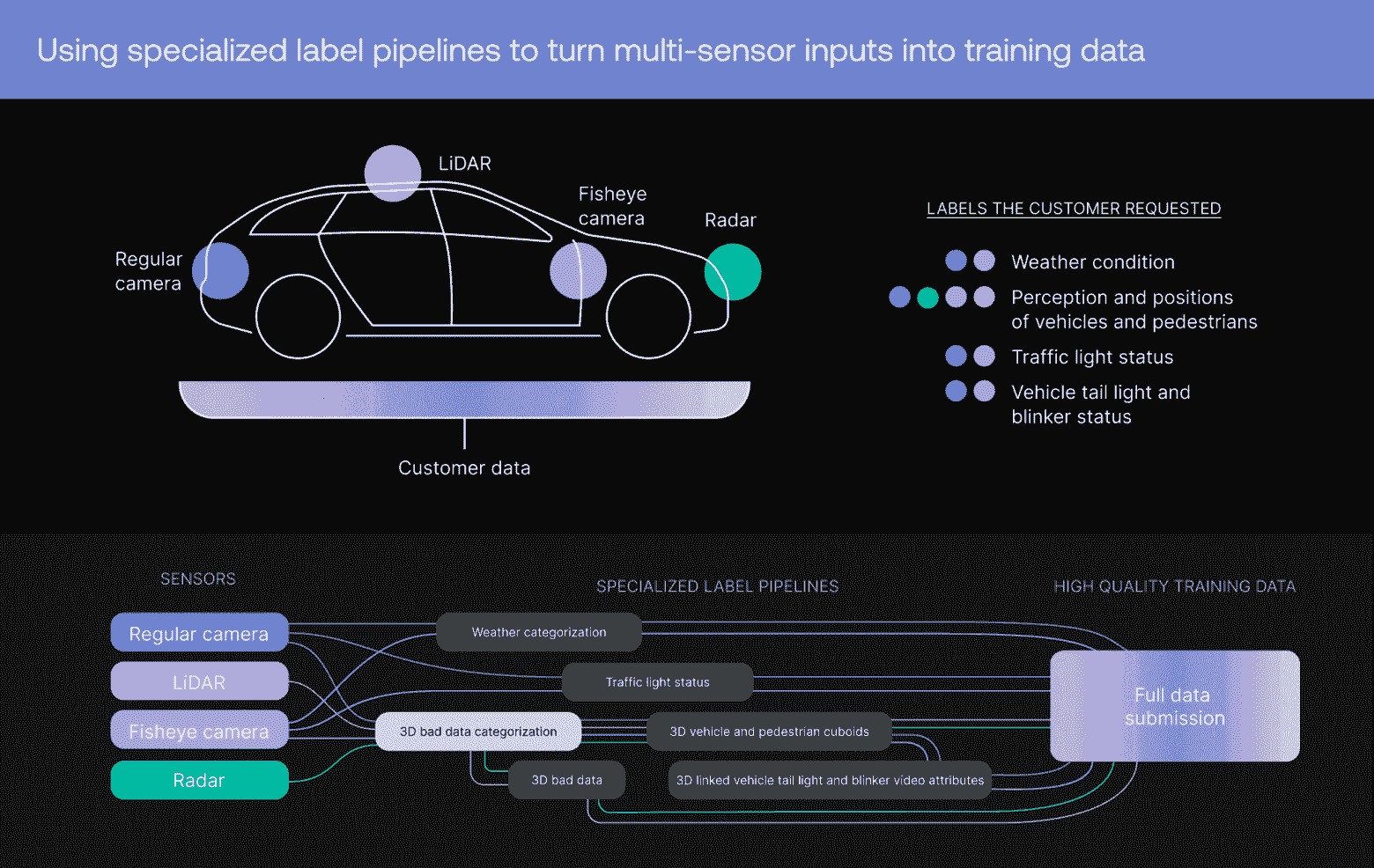
Scale стремится понять сроки выполнения задач клиентов в области машинного обучения и спроектировать конвейеры разметки, рассчитанные на конкретные потребности в данных для каждой задачи.
Важно заметить, что очень немногие клиенты приходят к нам с чётко очерченными простыми требованиями к конвейеру. Сегодня наши клиенты приносят комбинированные данные от множества разных датчиков. Для клиентов из сферы беспилотного транспорта это могут быть данные лидаров, радаров, сочетания данных камер с обычными объективами и объективами «рыбий глаз». Наличие чёткого понимания целей наших клиентов помогает нам быть генератором идей о типах объектов или событий, которые необходимо размечать для этих датчиков. Также это помогает нам предлагать архитектуру конвейера, включающего в себя наилучшие свойства продукта для создания всеобъемлющего, нацеленного на задачу массива данных обучения.
Например, мы можем предложить реализацию последовательности зависимых конвейеров, соединяющих вместе категоризацию, 3D-кубоиды лидаров и сопоставление данных лидаров. Погодные атрибуты и дефекты 3D-данных можно выявлять и категоризировать в конвейере категоризации, транспорт может отслеживаться в проекте обработки 3D-кубоидов LiDAR, а определяемые камерой атрибуты, например, состояние сигнала поворота, может генерироваться в проекте сопоставления.

Клиенты из сферы беспилотного транспорта часто приходят в Scale, имея на руках данные от множества датчиков и с пониманием того, что им нужно. Далее команда Scale проектирует специализированные конвейеры разметки, соединяющие эти два аспекта, быстро и эффективно создавая высококачественные размеченные данные.
Мы тестируем и настраиваем архитектуру конвейеров, создавая «золотой» массив данных и анализируя его с нашими клиентами
Применение этого продуманного подхода к реализации потребностей клиента помогает нам достичь важного этапа в обработке данных: создания «золотого» массива данных. «Золотой» массив используется в качестве эталонных «хороших данных». Он служит опорным материалом для нас, наших разметчиков и руководства клиента.
Создание «золотого» массива данных — это исследовательский процесс. Мы приступаем к созданию «золотого» массива с аннотирования репрезентативной выборки данных в спроектированном нами конвейере. Аннотирование данных всегда позволяет делать наблюдения и выводы о нюансах в данных и требованиях к ним, которые мы сообщаем клиенту наряду со своими рекомендациями. Затем мы анализируем получившиеся аннотированные данные с клиентом, связывая рассматриваемые вопросы и рассуждения с целями клиента в машинном обучении.
Важнейшим аспектом является совместный анализ с клиентом предложенного «золотого» массива данных. Например, мы работали с клиентом из сферы производства автономных дронов, которому требовалась разметка многоугольниками пригодного к полётам пространства, то есть такого, где могут безопасно перемещаться дроны. Мы отрисовывали попиксельно точные многоугольники вокруг каждой ветки, однако клиент забраковал все наши труды. Только после совещания с клиентом вживую мы осознали, что для него качественные данные обучения — это многоугольники с большим отступом от пикселей деревьев, то есть приблизительные, простые многоугольники, которые просто не отрезают кроны деревьев! Одного этого совещания оказалось достаточно, чтобы проект вернулся в нужное русло и пошёл по пути к согласованным, релевантным и точно размеченным данным.
Получение этого совместно создаваемого «золотого» массива — очень мощный инструмент. Он используется для наших инструментов обучения и оценки работы живых разметчиков, обеспечивая и разметчикам, и эксплуатационному отделу чёткое понимание того, как должна выглядеть успешный результат. Также он помогает ориентироваться нашему отделу контроля качества (QA), задача которого заключается в воспроизведении работы отделов QA клиентов, чтобы мы могли снизить трудозатраты клиента, связанные с управлением данными.

Анализ примеров разметки совместно с клиентами помогает выбрать «золотой» массив данных, который, в свою очередь, позволяет расширить масштабы создания высококачественных меток.
Мы задействуем всех необходимых руководителей, чтобы обеспечить согласованность клиентов с нашей компанией и друг с другом
Мы осознаём, что наши клиенты занимаются сложными проектами, в которых задействовано множество руководителей из разных команд, в том числе отделов проектирования, разработки, поставок и юридических отделов. Согласование не считается завершённым, пока наша компания не согласуется с каждой командой в организации клиента и пока команды в организации клиента не согласуются друг с другом.
Проекты могут завершиться провалом, если валидирующий отдел клиента проверяет размеченные данные в соответствии с набором стандартов, отличающимся от ожидаемого отделом машинного обучения. Эта проблема может проявляться по-разному: например, валидирующий отдел может проверять слишком мягко (допустим, утверждая слишком свободно размеченные многоугольники) или слишком жёстко (например, отвергая прямоугольники нужного размера), или просто выполняя проверку по другому или устаревшему стандарту (например, используя старое определение понятия «грузовик», к которому ранее относились небольшие пикапы).
В результате применения несогласованных стандартов разметки команда машинного обучения получает данные обучения, не улучшающие производительность модели. Или у команды машинного обучения возникает дефицит данных, несмотря на то, что есть данные, способные улучшить производительность! Нет ничего хуже, чем неделями или месяцами поставлять данные и постоянно получать их одобрение от валидирующего отдела клиента, а потом получить массовый отказ от команды машинного обучения, когда она начнёт тестирование производительности модели.
Scale повышает согласованность руководителей отделов, приглашая к обсуждению нужных людей, особенно на этапах, имеющих высокую долю риска. Также мы активно отслеживаем признаки возможной несогласованности (например, отсутствие связи с некоторыми руководителями в важные для проекта моменты) и работаем над тем, чтобы клиенты повышали согласованность как внутри своей организации, так и со Scale. Мы гордимся тем, что являемся осведомлённым партнёром, знающим, как избегать ситуаций, замедляющих разработку ИИ-приложений.
Согласование — это не результат, а процесс; мы постоянно продолжаем оценивать согласованность с целями нашего клиента в области машинного обучения
Для сохранения согласованности требуются намеренные усилия. Очень часто оценки производительности модели заставляют клиентов изменять требования к данным и инструкции по разметке. И даже когда инструкции по разметке остаются неизменными, могут меняться сами данные клиента. Например, однажды мы создали надёжный высококачественный конвейер для разметки изображений с улиц, однако следующий пакет данных клиентов содержал сцены с людьми, лежащими на беговой дорожке.
На протяжении всего жизненного цикла конвейера аннотирования данных мы продолжаем применять процесс согласования. Мы продолжаем сверяться с целями клиента в области машинного обучения, улучшать структуру конвейера, поддерживать точность «золотого» массива данных и обеспечивать согласованность между командами на стороне клиента, Scale и разметчиков. Это увеличивает скорость получения нашими клиентами высококачественных размеченных данных, что, в свою очередь, ускоряет разработку ИИ-приложений.